기술 스택
Amazon Redshift
Redshift Serverless
WLM
Concurrency Scaling
프로젝트 개요
기존의 단일 Redshift 클러스터는 광고, 게임 로그, CDC 등 다양한 데이터를 처리하며 성능 저하와 확장성 한계에 직면했습니다. 본 프로젝트는 모든 데이터 워크로드를 안정적이고 유연하게 처리할 수 있는 멀티 클러스터 아키텍처로 전환하는 것을 목표로 했습니다.
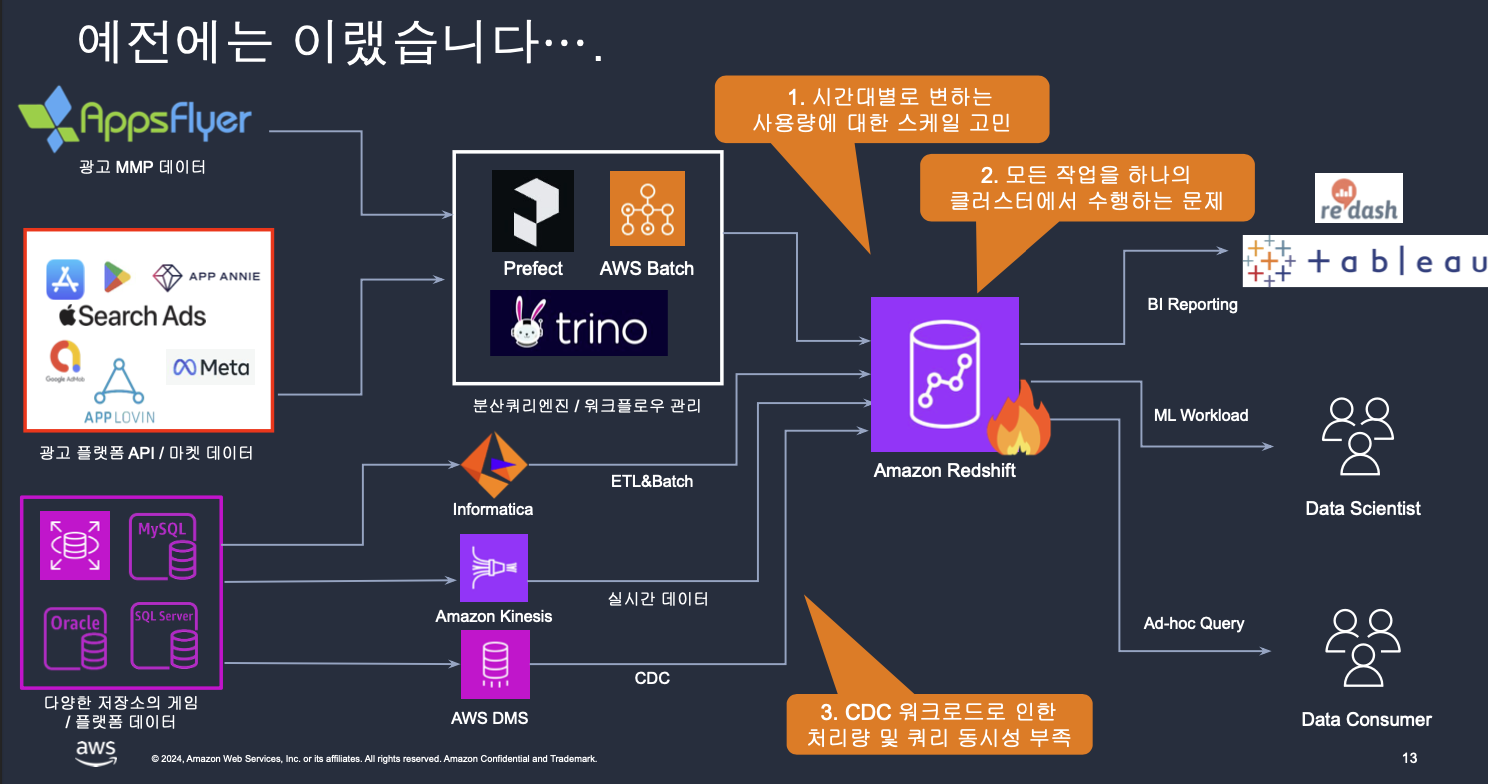
기존 아키텍처 (As-Is):
프로젝트 목표
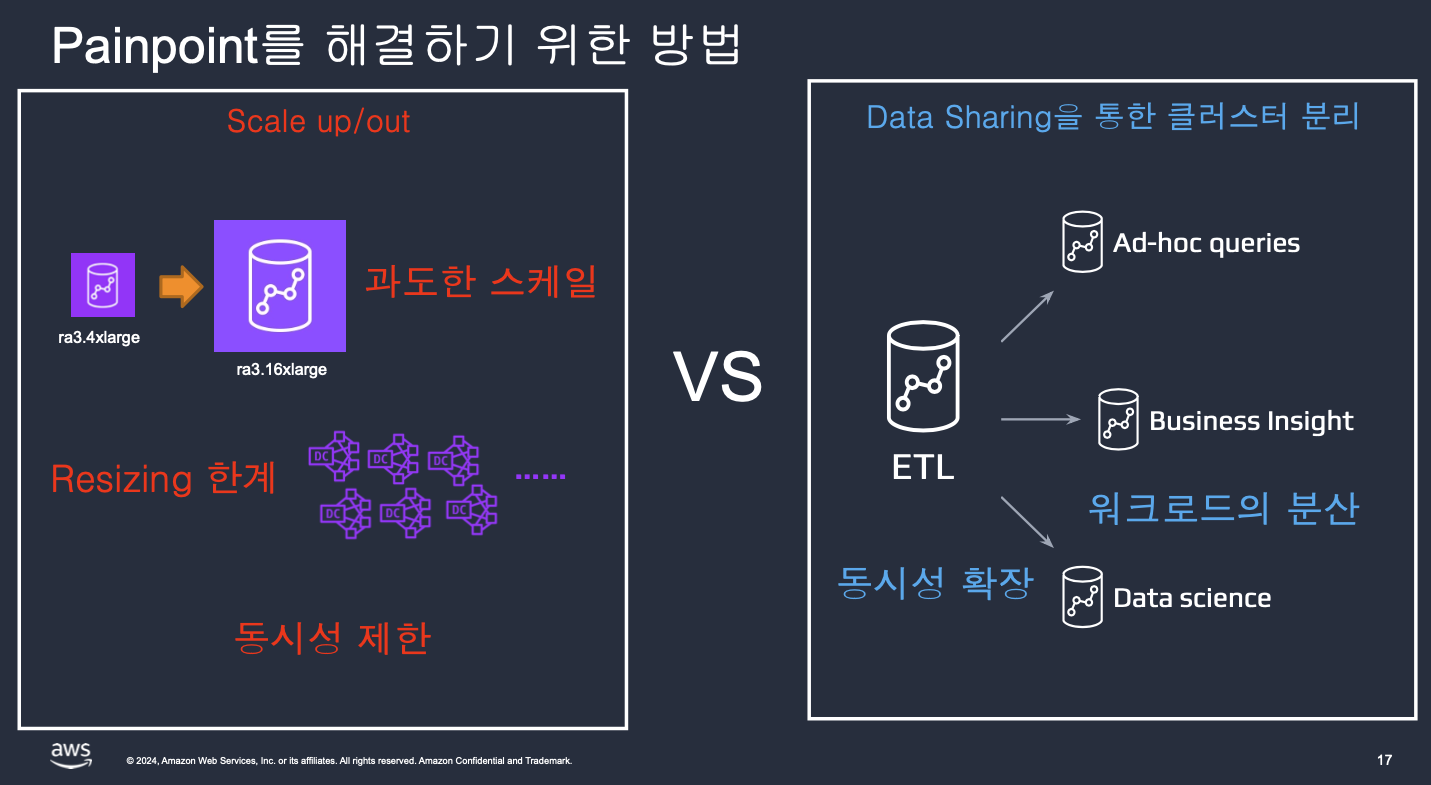
- 워크로드 분리 및 확장성 확보: Redshift Serverless와 Data Sharing을 활용해 역할 및 목적별 클러스터를 분리하고, 동시성 문제를 해결하여 급증하는 트래픽에 대응합니다.
- Zero-ETL 기반 데이터 통합: 복잡한 ETL 파이프라인의 부담을 줄이고, Aurora DB와 Redshift 간의 직접적인 데이터 통합으로 실시간에 가까운 분석 환경을 제공합니다.
- 운영 안정성 제고: 멀티 클러스터 아키텍처로 전환하는 과정에서 다운타임을 최소화하고, 기존 1,000개 이상의 워크플로우와 13,000개 이상의 테이블에 대한 안정성을 보장합니다.
기술적 도전과 해결 과정
1. 스케일링 문제와 워크로드 병목 현상
- 문제: 특정 시간대(오전 9~12시)에 사용량이 폭증하며 클러스터 전체의 성능이 저하되고, 모든 작업이 단일 클러스터에서 수행되어 동시성 부족 문제가 발생했습니다.
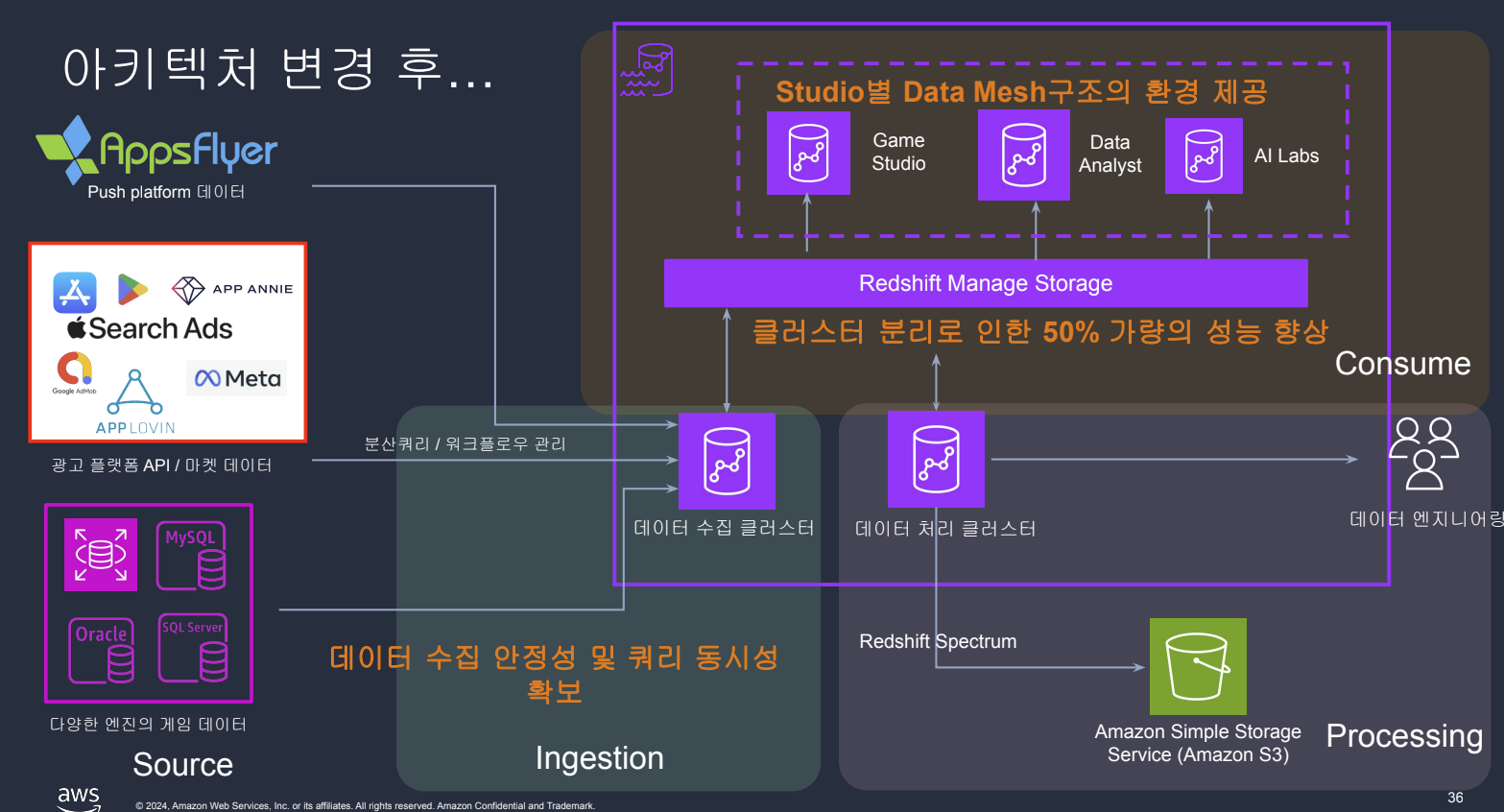
- 해결: Redshift Serverless와 Data Sharing을 도입하여 역할별(ELT, BI, AI/ML) 클러스터로 부하를 분산했습니다. 이를 통해 쿼리 성능을 약 50% 향상시키고 안정적인 운영이 가능해졌습니다.
2. CDC(Change Data Capture) 워크로드 부하
- 문제: CDC 데이터 처리 시 다단계 변환 및 로딩 과정에서 처리량 한계와 동시성 제한이 발생했습니다.
- 해결: Concurrency Scaling 을 도입하여 동시성을 확보하고 Zero-ETL을 도입하여 OLTP DB(Aurora)와 Redshift를 직접 통합함으로써 CDC 처리 과정의 병목을 해소하고 데이터 동기화 지연을 최소화했습니다.
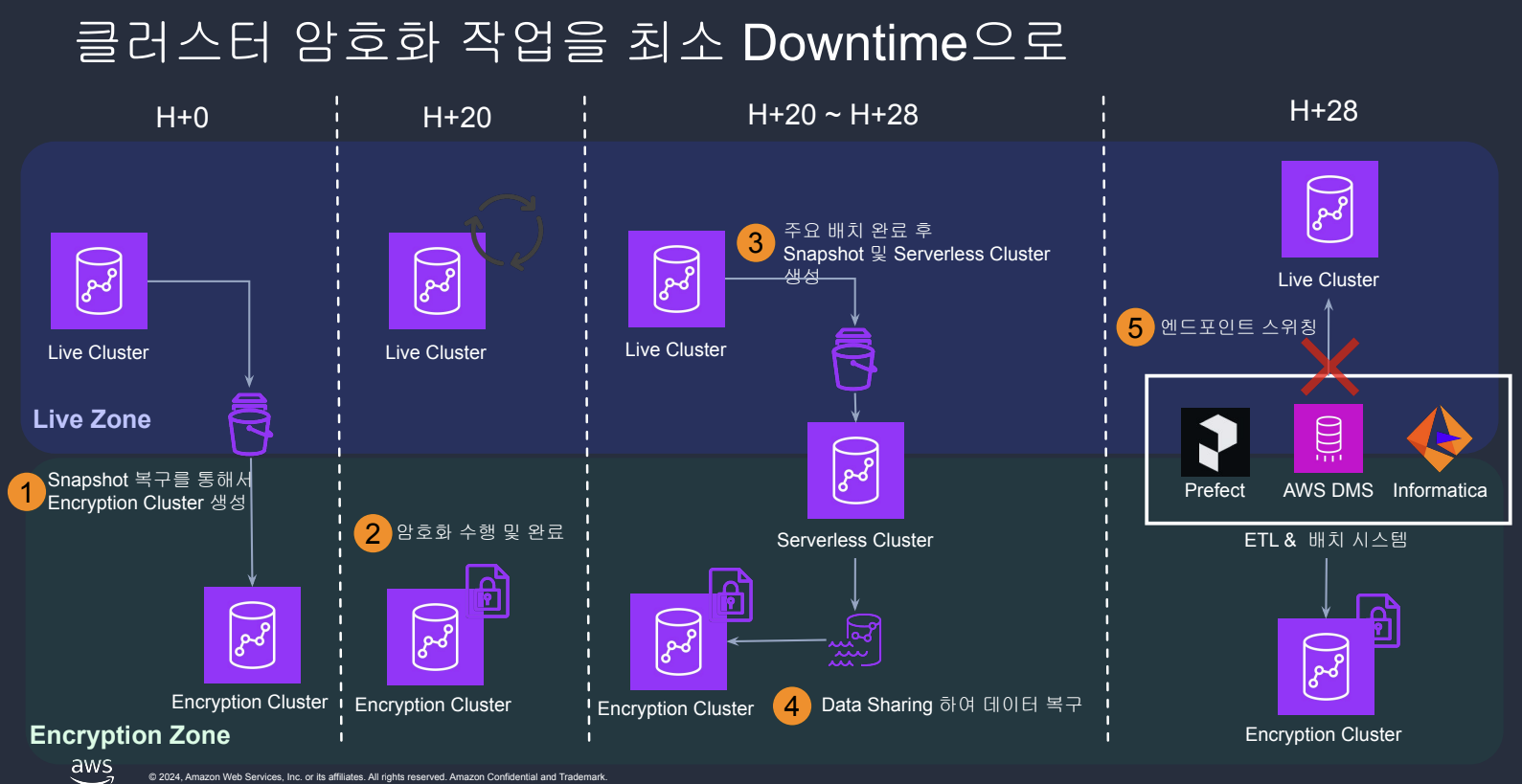
3. 180TB 클러스터 암호화 전환의 어려움
- 문제: Data Sharing 및 Zero-ETL을 적용하기 위해 필수적인 암호화 과정에서 최대 180TB에 달하는 대규모 데이터로 인해 장시간의 다운타임과 CPU 점유율 100%로 인한 서비스 장애가 우려되었습니다.
- 해결:
- 1단계 (사전 최적화): Distkey 재설정, 수동 Vacuum, 데이터 라이프사이클 관리를 통해 40TB 이상의 불필요한 데이터를 정리하여 암호화 대상을 최소화했습니다.
- 2단계 (암호화 전략): Snapshot 기반으로 암호화된 클러스터를 생성하고, 이를 Serverless 클러스터로 복구한 뒤, 엔드포인트 스위칭 방식으로 서비스를 전환하여 다운타임을 30분 이내로 최소화했습니다.
성과 및 임팩트
- 성능 50% 향상: 멀티 클러스터를 통한 워크로드 분리 및 동시성 확보를 통해 핵심 쿼리 성능을 약 50% 개선했습니다.
- 운영 안정성 강화: 암호화간 최소한의 다운타임으로 데이터 수집 안정성을 확보하였고 향후 리소스 확장에도 유연하게 대응할 수 있는 기반을 마련했습니다.
- 데이터 매쉬 구조 마련: 스튜디오별 클러스터를 부여하여 데이터 거버넌스를 개선하고, 비용 및 성능 효율을 극대화할 수 있는 데이터 매쉬 구조를 마련했습니다.
개선된 아키텍처 (To-Be):
배운 점과 향후 개선 방향
배운 점
- 유연한 아키텍처의 가치: 단일 클러스터의 확장성의 한계를 느끼며 현대적 데이터 플랫폼은 유연하고 확장 가능한 아키텍처가 필수적임을 깨달았습니다.
- 데이터 관리의 중요성: 암호화 작업을 위해서 데이터 정리 및 워크플로우 리스트 업을 하며
data observability의 필요성을 느꼈고data life cycle도 거버넌스 적인 관점에서 관리해야함을 배웠습니다. 이 것이 선행되어 있다면 더 빠르게 멀티 클러스터 전환을 이루지 않았을까 하는 아쉬움이 남습니다.
향후 개선 방향
- 데이터 메시(Data Mesh) 효율화: 데이터 거버넌스를 개선하고, 각 스튜디오 별로 데이터에 대한 오너십을 강화하여 비용 및 성능 효율을 극대화할 계획입니다.
- Data Sharing 쓰기 기능 도입: 멀티 클러스터 환경에서 양방향 데이터 쓰기를 구현하여 진정한 의미의 멀티 클러스터와 데이터 통합을 실현합니다.