기술 스택
Prefect
ElasticSearch
Redis
Prometheus
RDS Snapshot
API Integration
개요
단일 데이터 소스로는 얻을 수 없는 깊이 있는 비즈니스 인사이트를 확보하기 위해, 15개 이상의 내/외부 이종 데이터 소스를 통합 수집하는 파이프라인들을 구축했습니다. 각 데이터 소스의 고유한 API 제약, 데이터 구조, 수집 주기를 고려한 맞춤형 수집 전략을 통해, 파편화된 데이터를 연결하여 비즈니스의 전체 그림을 볼 수 있는 기반을 마련했습니다.
주요 데이터 소스 및 수집 전략
데이터 엔지니어로서 각 소스의 기술적 특성과 비즈니스적 중요도를 파악하고, 안정성과 효율성을 모두 고려한 맞춤형 수집 파이프라인을 설계했습니다.
1. ElasticSearch
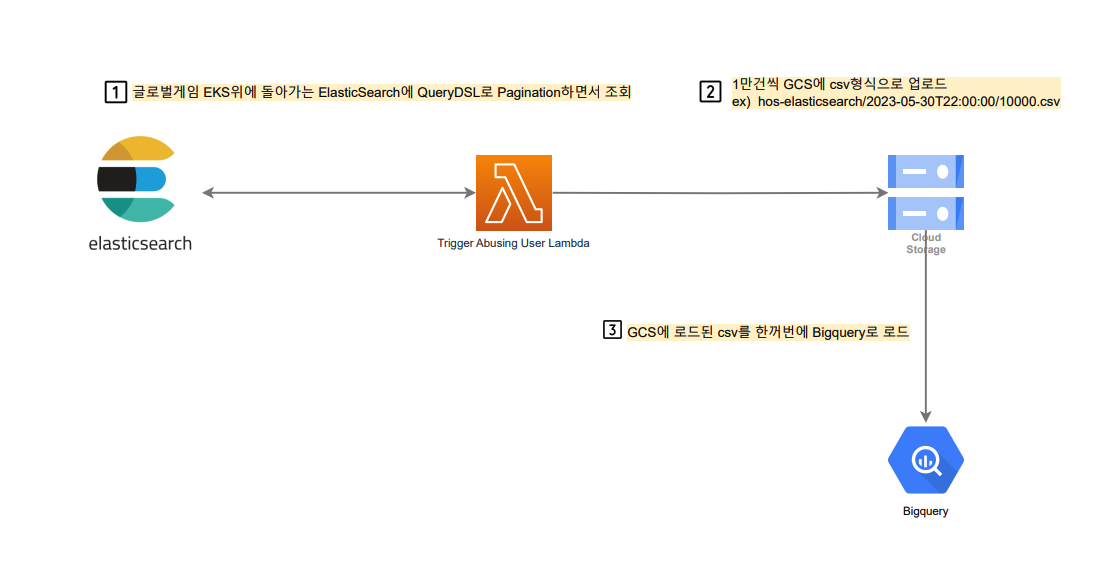
- 목적: 게임 클라이언트 및 서버에서 발생하는 대용량 비정형 로그를 분석용 데이터로 변환.
- 도전 과제: 실시간으로 쌓이는 대용량 로그를 프로덕션 클러스터에 영향을 주지 않고 효율적으로 추출해야 했습니다. 또한, 중첩된 JSON 구조의 로그를 분석하기 쉬운 정형 데이터로 변환하는 과정이 필요했습니다.
- 해결 방안:
- Scroll API 활용: 대용량 데이터 추출 시 메모리 부하를 최소화하기 위해
Scroll API를 사용하여 페이지네이션 방식으로 데이터를 안정적으로 가져왔습니다.
- Scroll API 활용: 대용량 데이터 추출 시 메모리 부하를 최소화하기 위해
2. Google Play & Apple App Store
- 목적: 앱 리뷰, 평점, 다운로드 수 등 경쟁 분석 및 사용자 피드백 파악에 필수적인 마켓 데이터 수집.
- 도전 과제: 각 마켓 콘솔에서 제공하는 보고서 내용을 다운받아서 DW에 활용 가능한 형태로 변환해야 했습니다. 또한 여러 계정에서 데이터를 수집해야 하므로 계정 연동에 어려움이 있었습니다.
- 해결 방안:
- 데이터 수집 자동화: google play 같은 경우는 여러 계정에서 bigquery transfer를 활용하여 적재하고, apple app store는 app store connect api 통해 데이터를 수집했습니다.
- 데이터 모델 표준화: 각 계정을 공통계정으로 연동하는 가이드를 마련하여 5개가 넘는 계정에서의 보고서 데이터를 수집하였으며, Google과 Apple에서 수집된 데이터를
앱이름,평점,리뷰수등 공통된 필드를 가진 표준 스키마로 정규화하여 저장함으로써, 플랫폼에 구애받지 않는 통합 분석을 가능하게 했습니다.
3. Influx/Prometheus
- 목적: 서버, 데이터베이스 등 핵심 인프라의 CPU, 메모리, 네트워크 등 시계열(Time-series) 메트릭을 수집하여 시스템 상태 모니터링 및 이상 탐지에 활용.
- 도전 과제: 초 단위로 발생하는 방대한 양의 메트릭 데이터를 효율적으로 저장하고, 분석에 의미 있는 정보로 가공해야 했습니다.
- 해결 방안: Prometheus의
HTTP API와PromQL을 사용하여 필요한 메트릭만 집계(Aggregation)된 형태로 조회했습니다. 원본(Raw) 데이터가 아닌 1분, 5분 단위로 집계된 데이터를 수집하여 저장 데이터의 양을 최적화하고 분석 성능을 높였습니다.
4. Redis
- 목적: 실시간 랭킹, 사용자 세션 등 휘발성 데이터를 분석용으로 스냅샷을 생성하고 저장.
- 도전 과제: In-memory 데이터베이스인 Redis의 특성상, 대량의 데이터를 조회하는 작업은 프로덕션 서비스에 직접적인 성능 부하를 줄 수 있었습니다.
- 해결 방안:
KEYS명령어 대신, Blocking 없이 점진적으로 키를 스캔하는SCAN명령어를 사용했습니다. 또한, 프로덕션에 영향을 주지 않기 위해 Read Replica(복제본) 노드에서 데이터 추출 작업을 수행하여 서비스 안정성을 확보했습니다.
5. GeoIP & Proxy 데이터
- 목적: 사용자 접속 IP를 기반으로 국가, 도시 등 위치 정보를 파악하고, Proxy/VPN 사용 여부를 판별하여 부정 사용자를 필터링.
- 도전 과제: MaxMind와 같은 외부 GeoIP 데이터베이스는 주기적으로 업데이트되므로, 항상 최신 버전을 유지해야 했습니다.
- 해결 방안: 최신 DB 파일이 릴리즈되면 이를 자동으로 감지하여 S3에 다운로드하고, 이를 기반으로 데이터 웨어하우스의 IP 조회용 Lookup 테이블을 자동으로 업데이트하는 파이프라인을 구축했습니다.
6. SensorTower API
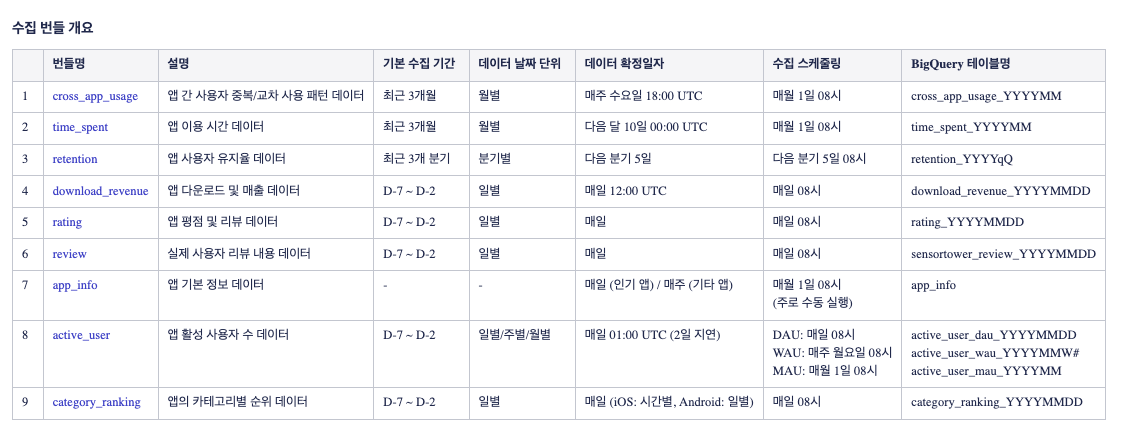
- 목적: 경쟁사 앱의 다운로드, 매출 추정치 등 외부 시장 정보를 수집하여 경쟁 전략 수립에 활용.
- 도전 과제: 다양한 요구사항에 맞춰 API 데이터를 제공하고, API수집 특성상 오류가 잦아 Backfill이 용이한 구조가 필요했습니다.
- 해결 방안: 사진과 같이 API 호출 범위를 리스트로 관리하고, 오류 발생 시 자동으로 재시도하는 로직을 구현했습니다.
7. 환율 데이터
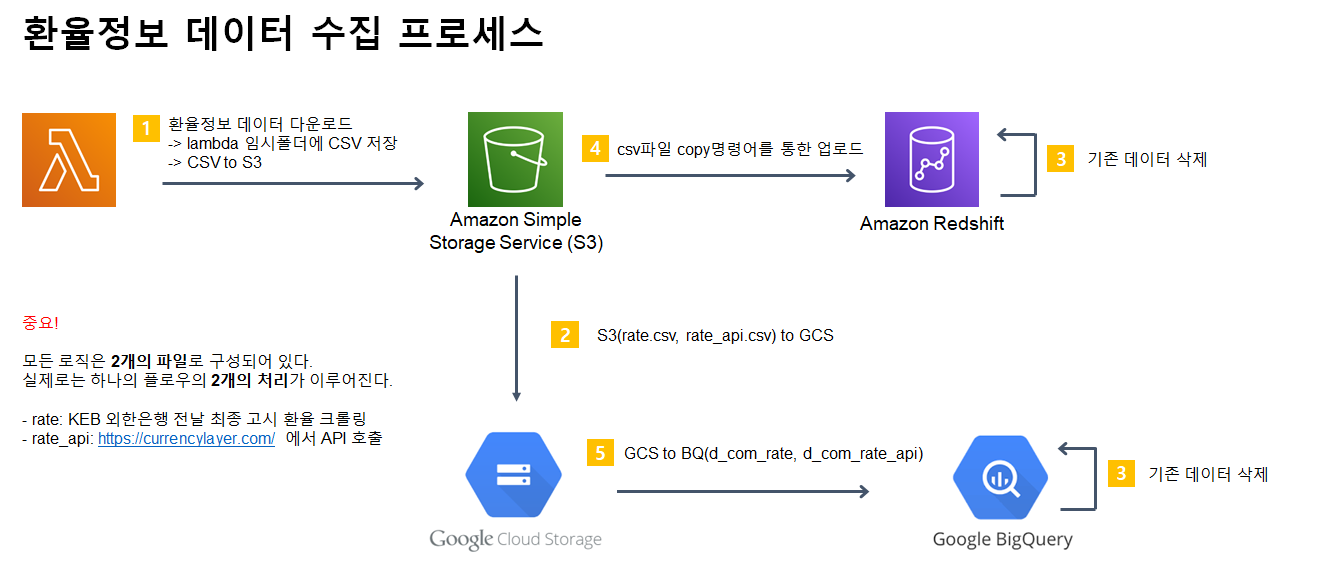
- 목적: 글로벌 서비스의 해외 통화 매출을 기준 통화(USD)로 환산하여 정확한 전체 매출을 집계.
- 도전 과제: 매일 변동되는 환율 정보를 안정적으로 수집해야 하며, 특정일의 환율 정보가 누락될 경우 매출 집계에 오류가 발생할 수 있었습니다.
- 해결 방안: 신뢰도 높은 금융 정보 API를 통해 매일 환율 정보를 수집하고, API 장애 시 대체 소스에서 정보를 가져오는 이중화 구조를 설계했습니다. 수집된 환율은 날짜별로 DW에 저장하여 과거 특정 시점의 매출도 정확하게 재계산할 수 있도록 했습니다.
8. RDS Snapshot
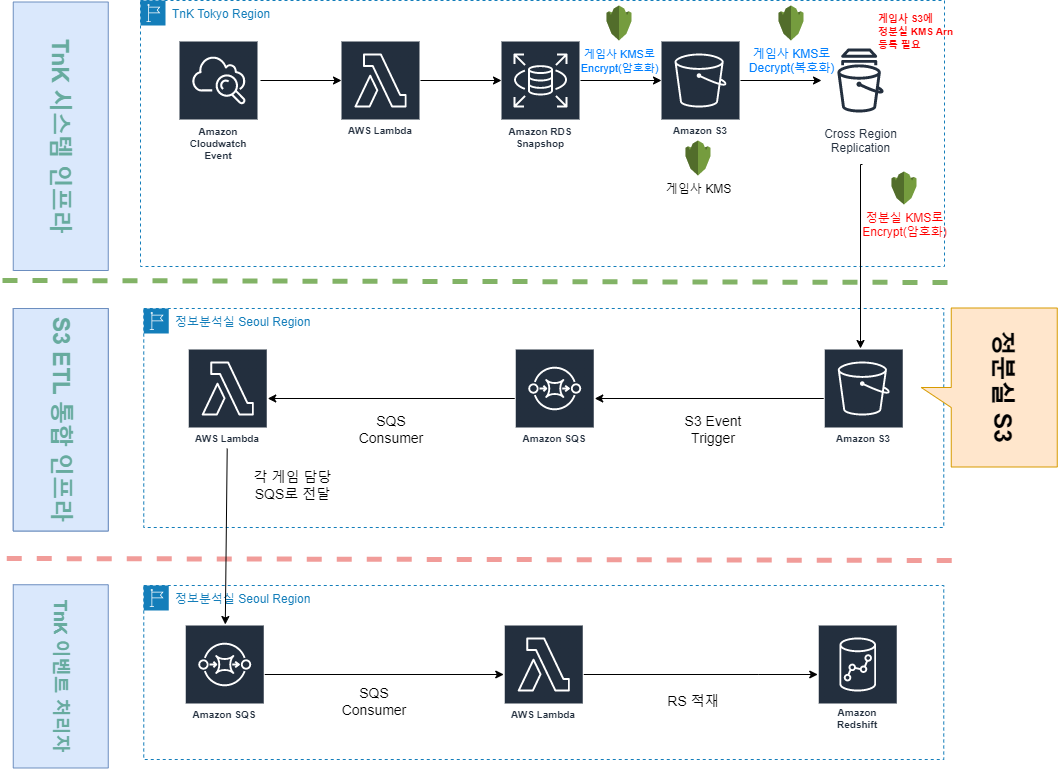
- 목적: 프로덕션 데이터베이스의 부하 없이 대규모 데이터를 데이터 웨어하우스로 이전.
- 도전 과제: 운영 중인 DB에 직접 대량의 SELECT 쿼리를 실행하는 것은 서비스 장애를 유발할 수 있습니다.
- 해결 방안: 매일 새벽에 생성되는 RDS 스냅샷을 S3로 Export한 뒤, S3에서 안전하게 데이터를 추출(ETL)했습니다. 스냅샷은 보관기간을 두어 데이터 저장 비용의 낭비도 막았습니다.
9. Google Play Voided Purchases API
- 목적: 사용자의 구매 취소(환불) 내역을 정확하게 반영하여 신뢰도 있는 매출 지표를 산출.
- 도전 과제: 환불 데이터는 일반 결제 데이터와 별도의 API를 통해 제공되므로, 두 데이터를 정확하게 동기화해야 했습니다.
- 해결 방안: 주기적으로 Voided Purchases API를 호출하여 환불된 거래 목록을 가져오고, 이를 데이터 웨어하우스의 원본 결제 데이터에 반영하여 환불된 거래를 명확히 식별(Flagging)하는 배치 파이프라인을 구축했습니다.