기술 스택
Terraform
Serverless Framework
Grafana
CloudWatch
AWS Cost Explorer
개요
이 문서는 특정 기간에 완료된 프로젝트가 아닌, 데이터 플랫폼의 안정성과 효율성을 보장하기 위해 팀내에서 지속적으로 수행하고 있는 인프라 관리, 모니터링, 그리고 비용 최적화 활동에 대해 기술합니다. 데이터 엔지니어로서 인프라를 단순히 사용하는 것을 넘어, 안정적이고 비용 효율적인 데이터 플랫폼을 구축하고 운영하는 것을 목표로 합니다.
주요 활동 및 시스템
1. IaC(Infrastructure as Code) 기반 인프라 관리
도입 사유: 수동으로 인프라를 관리할 때 발생하는 휴먼 에러를 방지하고, 여러 환경에 걸쳐 일관성 있는 인프라를 배포하기 위해 IaC를 도입했습니다. 모든 인프라 변경 사항을 코드로 관리하여 버전 관리, 변경 이력 추적을 가능하게 했습니다.
- Terraform
- 역할: 정적이고 핵심적인 인프라 리소스(VPC, Subnet, EC2, RDS, Redshift, ECS, IAM 등)를 관리합니다.
- 특징: 선언적 구문을 통해 인프라의 최종 상태를 정의하고, 모듈화를 통해 반복적인 리소스 생성을 효율화했습니다. S3와 DynamoDB를 Remote State 백엔드로 사용하여 상태 파일을 안전하게 관리하고 팀원 간의 동시성 문제를 해결했습니다.
- Serverless Framework
- 역할: Lambda, SQS, API Gateway 등 이벤트 기반의 동적인 리소스를 애플리케이션 또는 파이프라인 단위로 묶어 관리합니다.
- 특징: 특히 이벤트 기반의 데이터 파이프라인을 배포하고 관리하는 데 용이하며 서비스 단위로 빠르게 요구사항을 반영할 수 있었습니다. 각 함수에 필요한 IAM 권한만 최소한으로 부여하여 보안을 강화했습니다.
- Pulumi (PoC 진행중)
- 도입 배경: Serverless Framework의 유료화 정책 변경에 따라 대안을 모색하게 되었습니다. 또한, Python, Go 등 범용 프로그래밍 언어로 인프라를 정의할 수 있다는 점이 데이터 엔지니어링 팀의 생산성을 높일 수 있다고 판단했습니다.
- 현재 상태: Snowflake 도입에 맞춰 RBAC(Role-Based Access Control), Warehouse, Database 등의 리소스를 Python 코드로 관리하기 위한 PoC를 진행하고 있습니다. 이를 통해 데이터 엔지니어에게 친숙한 환경에서 인프라와 애플리케이션 로직을 함께 관리할 수 있는 가능성을 검증하고 있습니다.
2. 데이터 웨어하우스(DW) 모니터링
도입 사유: 데이터 웨어하우스는 데이터 분석의 핵심입니다. 성능 저하, 비용 급증, 데이터 정합성 문제를 사전에 방지하고 신속하게 대응하기 위해 다각적인 모니터링 시스템을 구축했습니다.
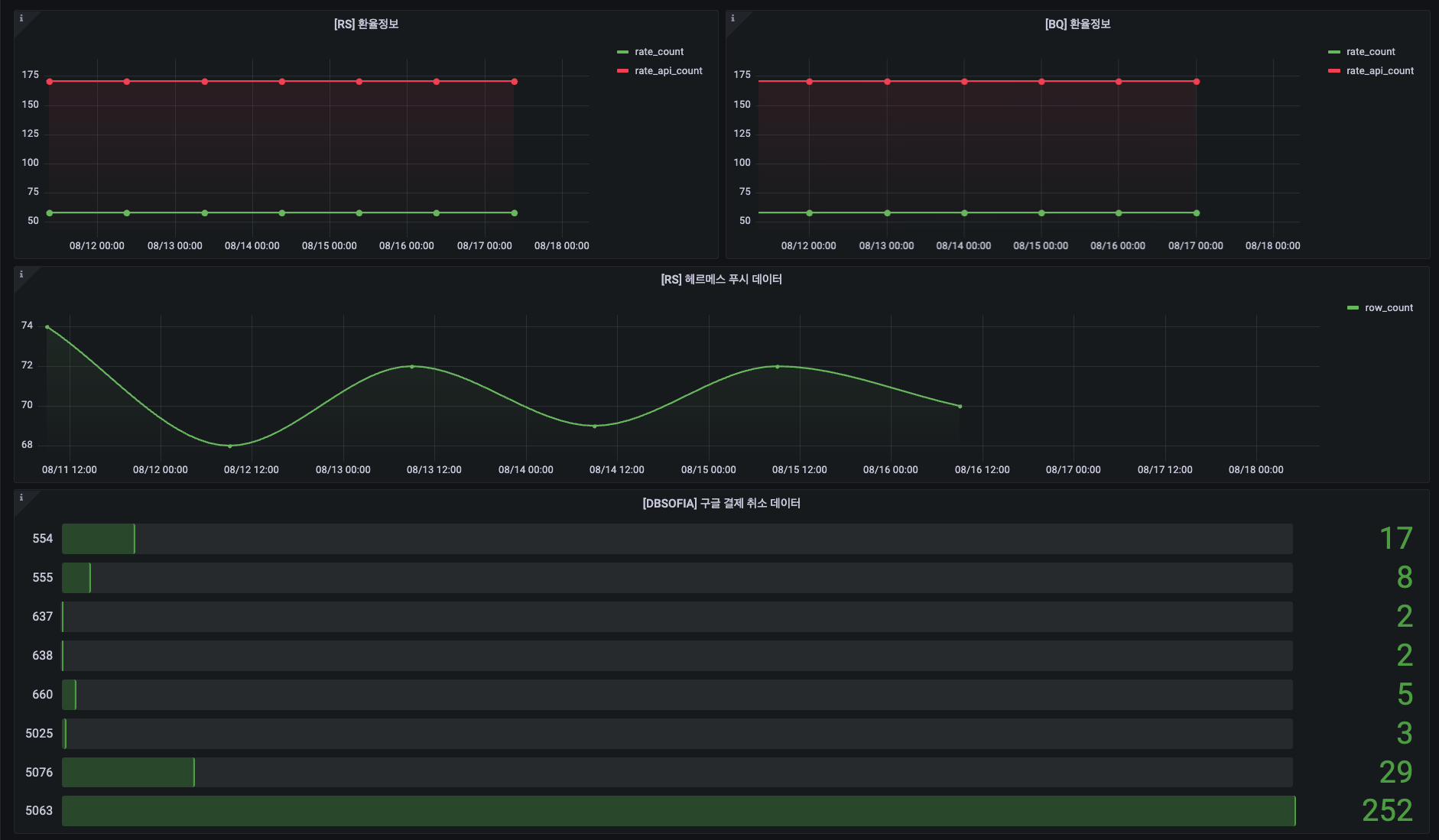
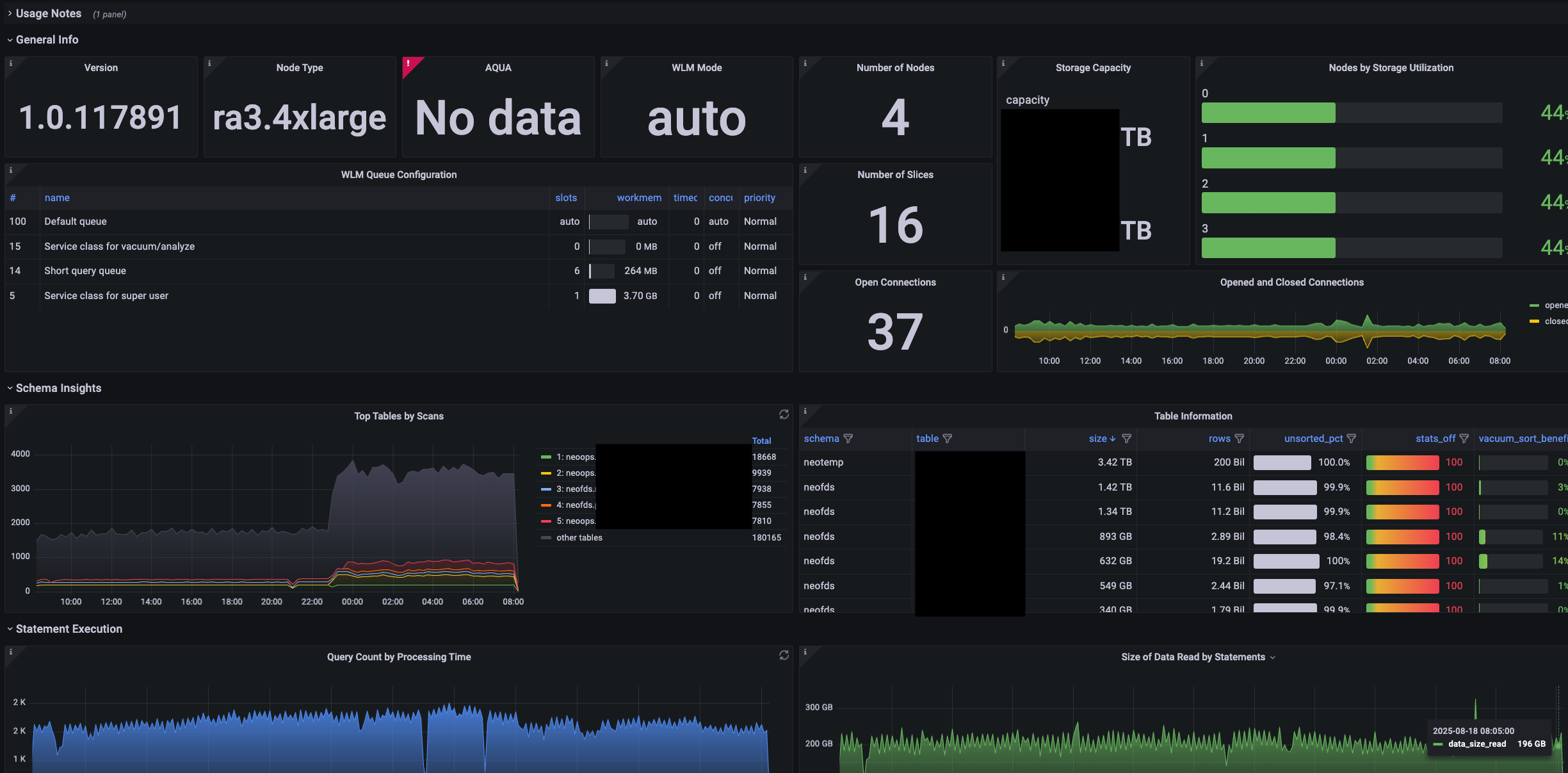
- 통합 쿼리 대시보드 (Grafana)
- Redshift 클러스터 관점: CPU/Memory 사용률, 디스크 공간, 활성 연결 수, WLM 큐 대기열 등 클러스터의 전반적인 상태를 시각화하여 병목 지점을 신속하게 파악합니다.
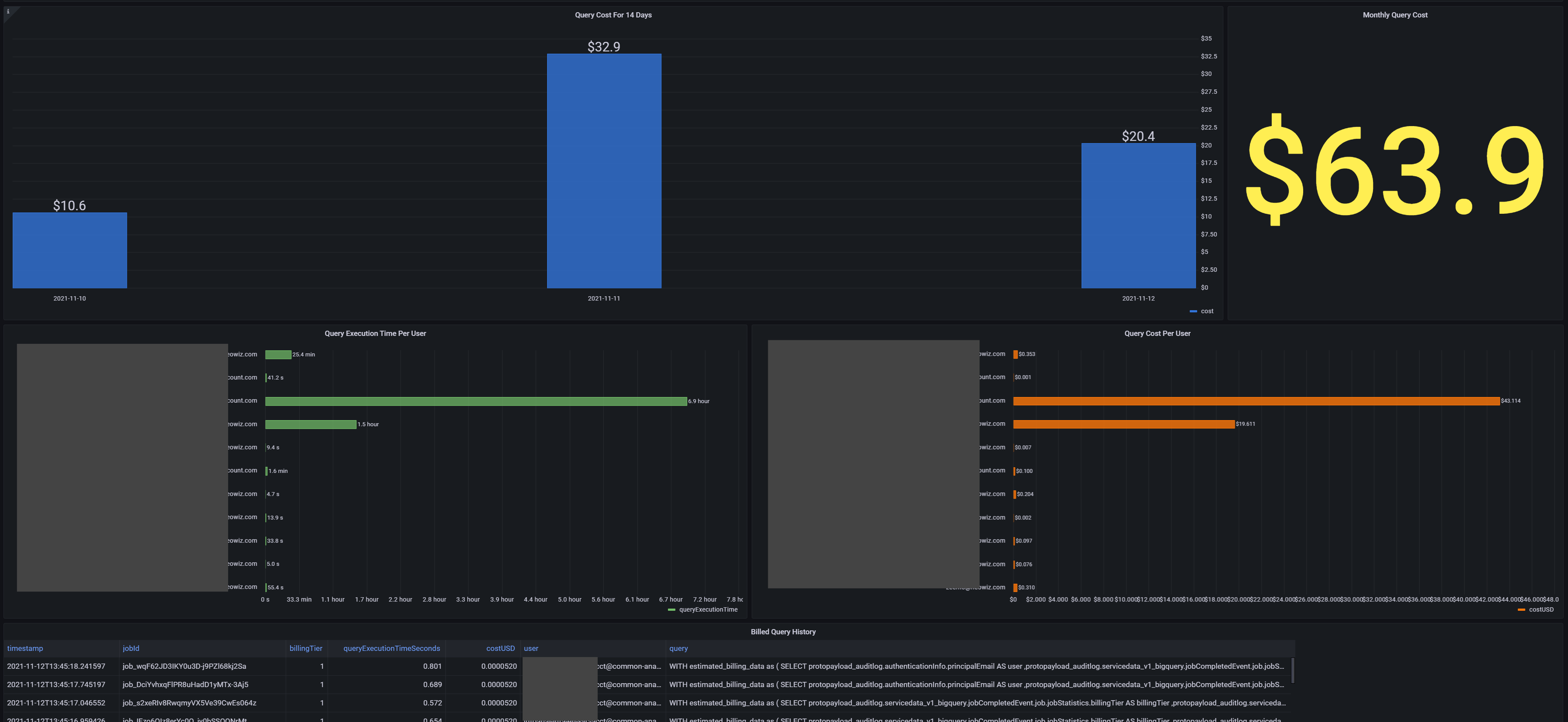
- BigQuery 비용 대시보드: 프로젝트별, 사용자별, 일자별 쿼리 비용을 추적하고, 예상치 못한 비용 급증을 조기에 발견할 수 있도록 구성했습니다.
- Redshift 클러스터 관점: CPU/Memory 사용률, 디스크 공간, 활성 연결 수, WLM 큐 대기열 등 클러스터의 전반적인 상태를 시각화하여 병목 지점을 신속하게 파악합니다.
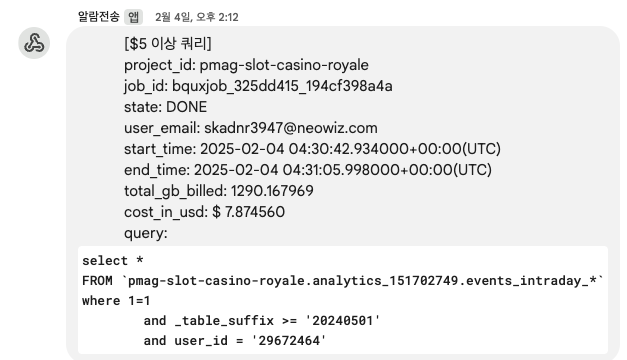
- 이상 쿼리 자동 알람
- 목적: 비용 낭비와 시스템 부하를 유발하는 쿼리를 실시간으로 탐지하고 담당자에게 알립니다.
- 구현:
BigQuery: 처리량이 $5를 초과하는 쿼리가 실행될 경우 Google Chat으로 즉시 알림.Redshift: 1시간 이상 실행되는 Long-running 쿼리나 테이블 Lock을 유발하는 쿼리를 탐지하여 알림으로써 장애를 사전에 예방합니다.
- 데이터 정합성 대시보드 (Grafana)
- 목적: 데이터 파이프라인의 신뢰성을 보장하기 위해 구축했습니다.
- 구현: 주요 파이프라인의 Source와 Target 데이터의 Row Count, 최신 업데이트 시간 등을 주기적으로 비교하여 불일치 발생 시 즉시 파악할 수 있도록 시각화했습니다.
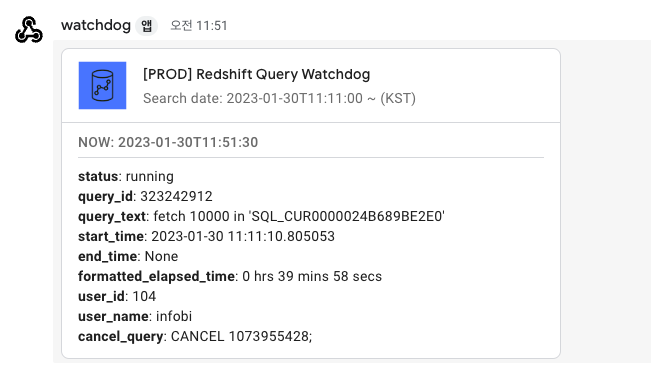
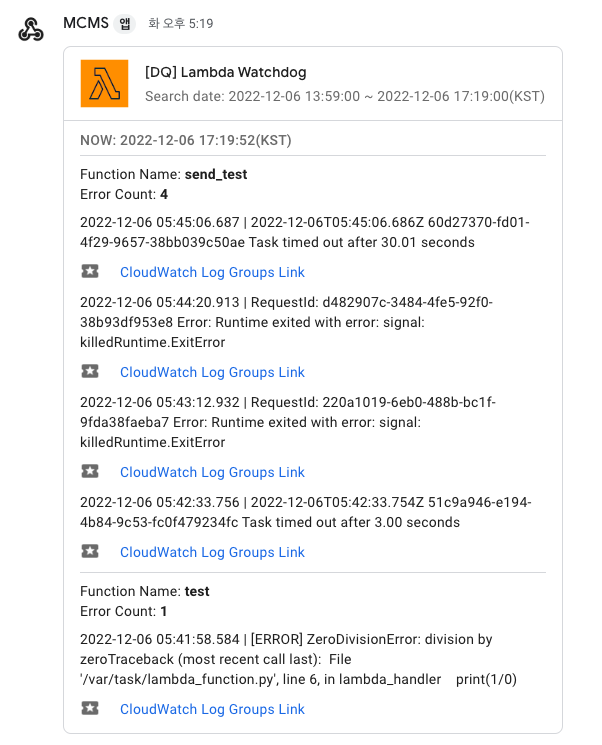
3. 데이터 파이프라인 모니터링
도입 사유: 매일 수백 개의 데이터 파이프라인이 실행되는 환경에서, 개별 파이프라인의 성공 여부와 성능을 추적하여 데이터 제공의 SLA(Service Level Agreement)를 준수하기 위해 구축했습니다.
- AWS Lambda 알람: CloudWatch를 통해 Lambda 함수의 에러 발생률, Timeout, Throttling 등 핵심 지표를 모니터링하고, 임계치 초과 시 즉시 알림을 받도록 설정했습니다.
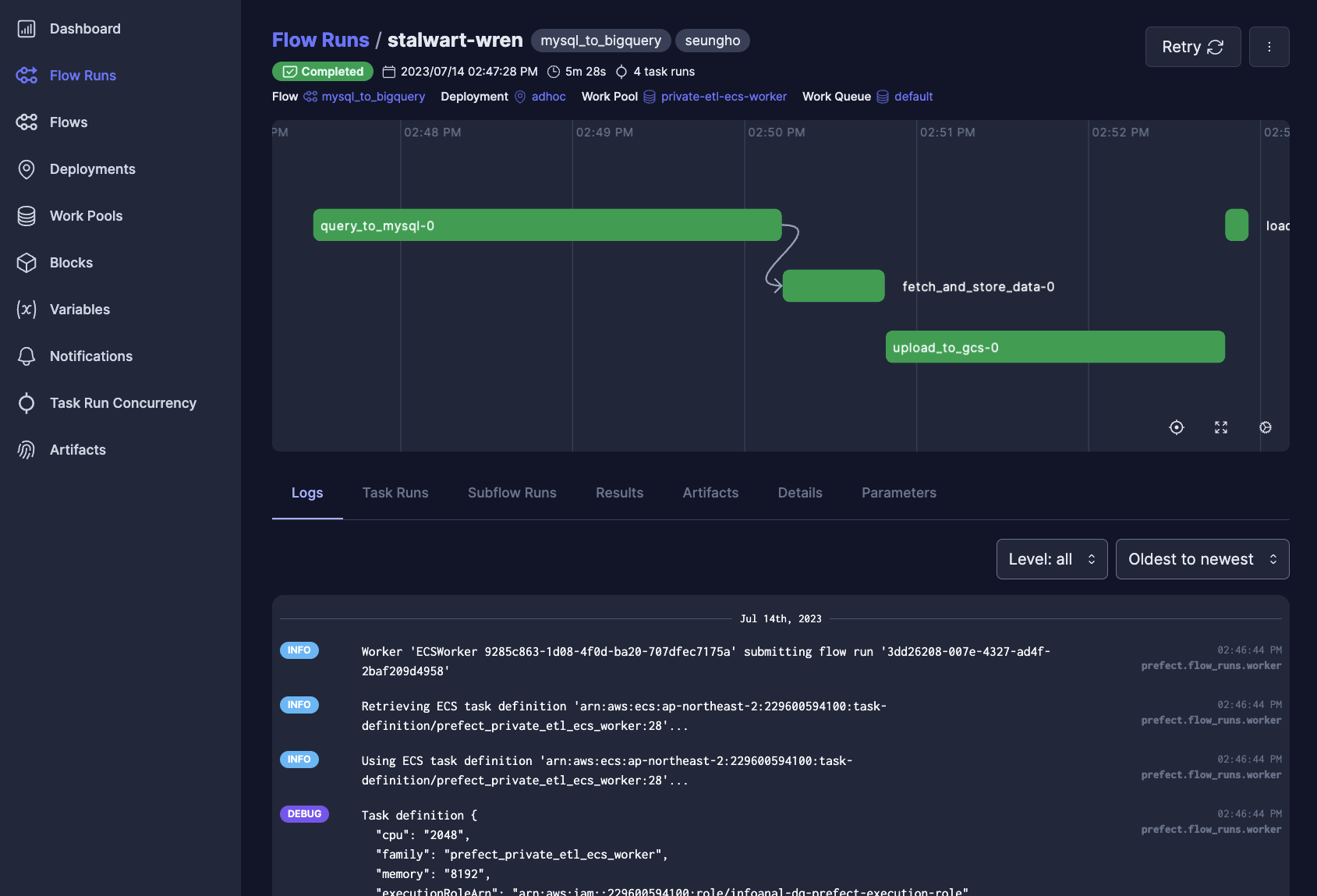
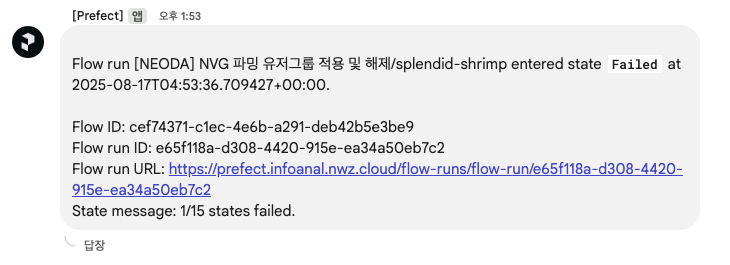
- Prefect 워크플로우 알람: 데이터 오케스트레이션 도구인 Prefect의 Automation 기능을 활용하여, 워크플로우(Flow)나 개별 태스크(Task) 실패 시 Google Chat으로 상세한 에러 로그와 함께 알림을 보내 신속한 디버깅을 지원합니다.
4. 지속적인 비용 최적화 활동
활동 목표: 클라우드 비용을 일회성으로 절감하는 것이 아니라, 지속적으로 비용 효율적인 아키텍처를 고민하고 불필요한 낭비를 자동화된 방식으로 관리하는 문화를 정착시키는 것을 목표로 합니다.
- Graviton 인스턴스 전환 테스트
- 내용: 기존 x86 기반 EC2, RDS 인스턴스를 AWS의 ARM 기반 프로세서인 Graviton으로 전환 시 얻을 수 있는 비용 및 성능 효과를 검증했습니다. 동일한 워크로드를 부여하여 CPU, 처리량, 응답 시간 등을 벤치마킹하고, 성능 저하 없이 20~30%의 비용 절감 효과를 확인한 후 단계적으로 전환하고 있습니다.
- 서버리스 아키텍처 우선 도입
- 전략: 신규 서비스나 파이프라인 설계 시, 유휴 상태에서 비용이 발생하는 EC2 대신 사용한 만큼만 비용을 지불하는 Lambda, Fargate, Aurora Serverless와 같은 서버리스 기술을 우선적으로 검토하여 비용 효율을 극대화합니다.
- 주기적인 유휴 리소스 자동 탐지 및 제거
- 내용: 정기적으로 실행되는 스크립트를 통해 연결되지 않은 EIP, Unattached EBS 볼륨, 오래된 S3 객체 등 불필요한 리소스를 자동으로 탐지하고 리포트합니다.
- 심화 활동: 사용량이 적은 EBS 볼륨의 경우, 스냅샷 생성 후 더 작은 볼륨으로 재생성하여 마운트하는 방식으로 EBS 볼륨 사이즈를 동적으로 최적화하여 비용을 절감했습니다. 또한, 개발 환경의 EC2/RDS는 업무 시간 외에는 자동으로 중지(Parking)되도록 설정하여 비용 낭비를 최소화했습니다.
- S3 Intelligent-Tiering 적용
- 내용: S3 객체의 접근 패턴을 분석하여 자주 사용되지 않는 객체를 자동으로 저비용 스토리지 클래스로 이동시킵니다. 이를 통해 스토리지 비용을 최적화하고, 데이터 접근 속도는 유지합니다. 하지만, Lifecycle 정책을 세우는 것은 어렵고 데이터의 비정기적인 접근이 필요한 점을 고려하여, Intelligent-Tiering을 적용했습니다.
- 성과: 별도의 데이터 변환 없이 스토리지 비용이 40% 절감되었으며, 데이터 접근 속도는 유지되었습니다.