기술 스택
AWS DMS
AWS Lambda
SQS
Google BigQuery
Python
Serverless Framework
프로젝트 개요
글로벌 카지노 게임 3종의 일배치 시스템을 준실시간 배치로 전환하는 멀티클라우드(AWS <-> GCP) 데이터 파이프라인을 구축했습니다. AWS DMS CDC, Lambda, SQS를 활용하여 RDS Aurora의 데이터를 Google BigQuery로 준실시간으로 이동시키는 고가용성 파이프라인을 설계 및 구현했습니다.
아키텍처
- RDS(MySQL) → DMS(CDC) → S3 → SQS → Lambda → Bigquery
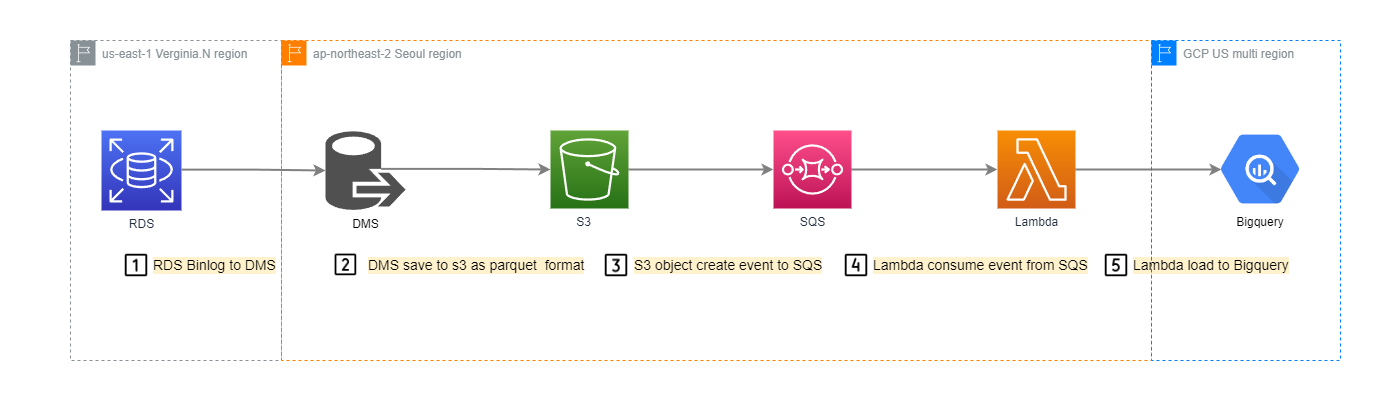
프로젝트 목표
- RDB에 저장된 데이터를 실시간으로 옮겨야 하는 미션
- PnE도입으로 인해 글로벌 카지노 게임 3종의 일배치를 준실시간 배치로 전환
- DB Cluster 6개
- 테이블 70여개
- 하루 데이터 4000만 row
기술적 도전과 해결 과정
1. 데이터 누락
- 문제: 빅쿼리 API 로드 오류 및 휴먼 에러로 인한 데이터 로드 실패
- 해결: S3와 Lambda 사이에 SQS 큐를 추가하여 실패한 이벤트를 재처리하도록 구성
2. 데이터 중복
- 문제: S3의 'at-least-once' 이벤트 보장 정책 및 재처리로 인한 데이터 중복 발생
- 해결: BigQuery의 Job ID를 고유 ID로 활용하여 중복된 Job 실행을 방지 (예:
yyyymmddhhmmss_{테이블}.parquet)
3. 테이블 관리
- 문제: 잦은 테이블 변동으로 인한 수동 배포의 비효율성
- 해결: 테이블 매핑 파일(json)을 분리하고, CD(자동 배포)를 구축하여 매핑 파일 수정 시 자동으로 배포되도록 개선
4. 자동 스키마 추론
- 문제: MySQL의 특정 데이터 타입(Bit, Boolean 등) 미지원 및 테이블 추가 시 수동 스키마 정의의 번거로움
- 해결: DMS의 공통 변환 기능과 Parquet 파일 변환 및 BigQuery의
autodetect스키마 추론 기능을 활용하여 테이블 자동 생성 및 데이터 타입 문제 해결
성과 및 임팩트
- 평균 Latency 1~2분 정도의 준실시간 배치 파이프라인 안정적으로 구축하여 실시간 대시보드 및 FDS(사기 탐지 시스템) 구현 기반 마련
- DW/BI 엔지니어의 ETL 파이프라인 관리 리소스 절감
- 분석가가 직접 테이블을 관리하도록 하여 데이터 엔지니어와의 의존성 감소
- 데이터 현황 모니터링 대시보드를 통해 데이터 수집 현황의 투명성 확보
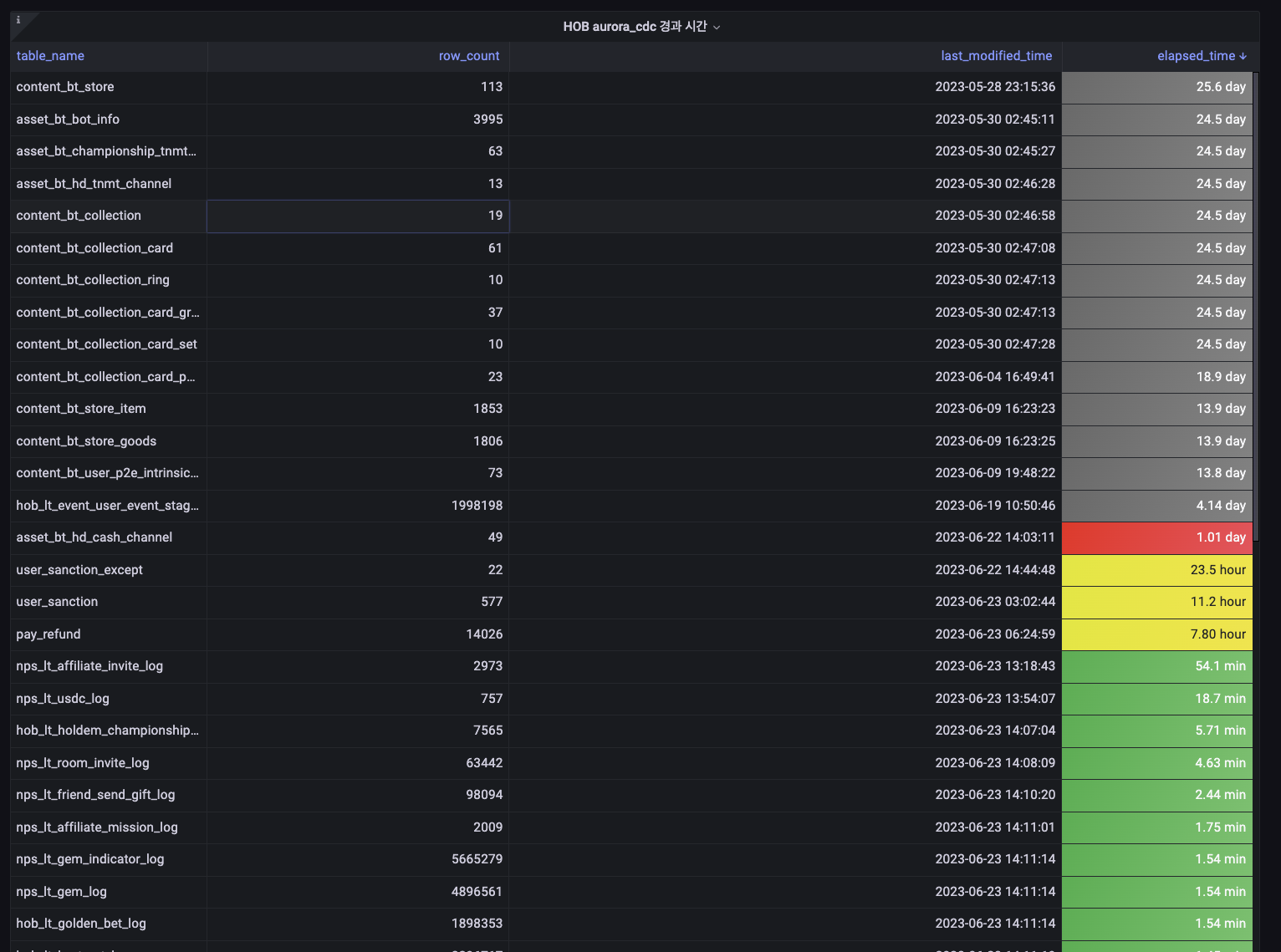
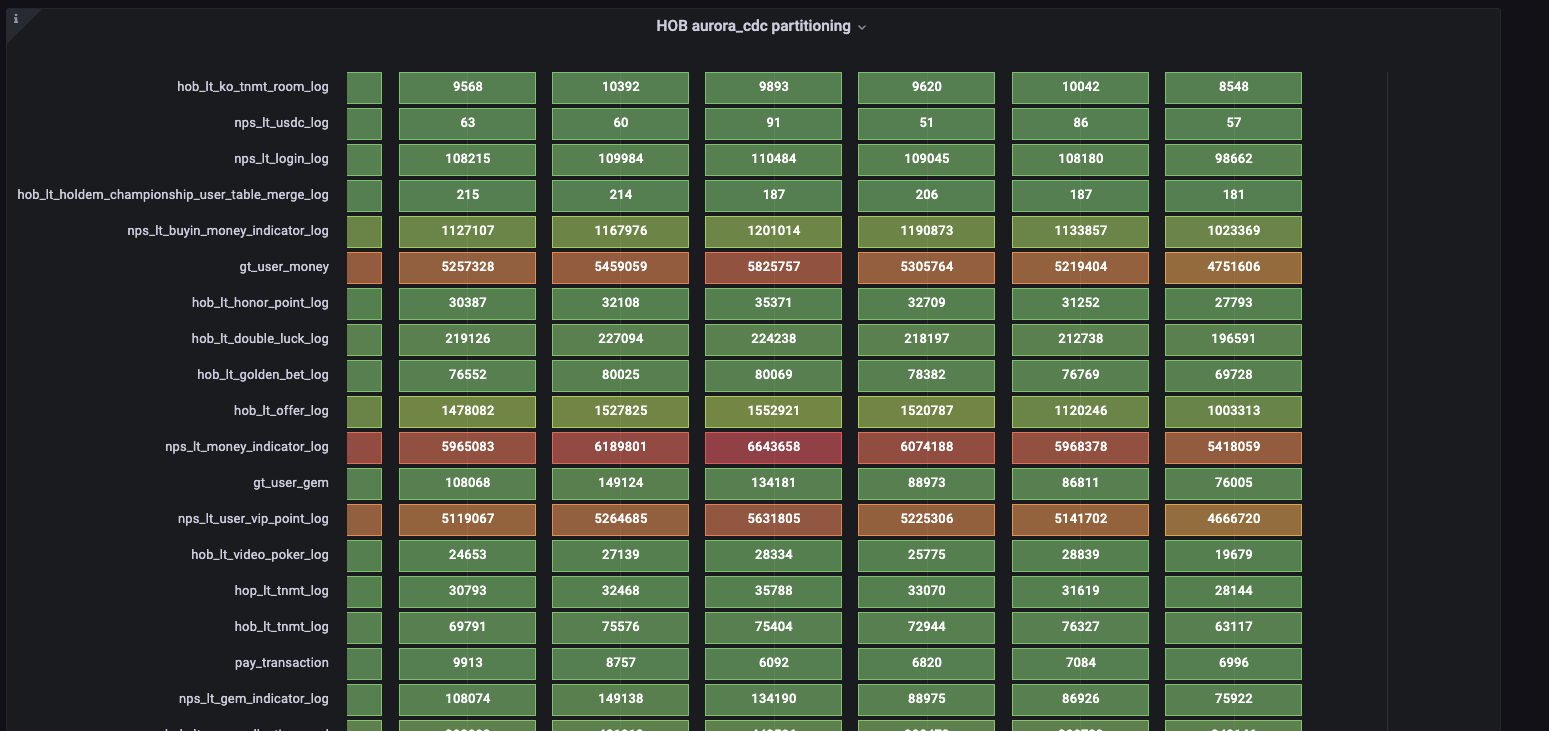
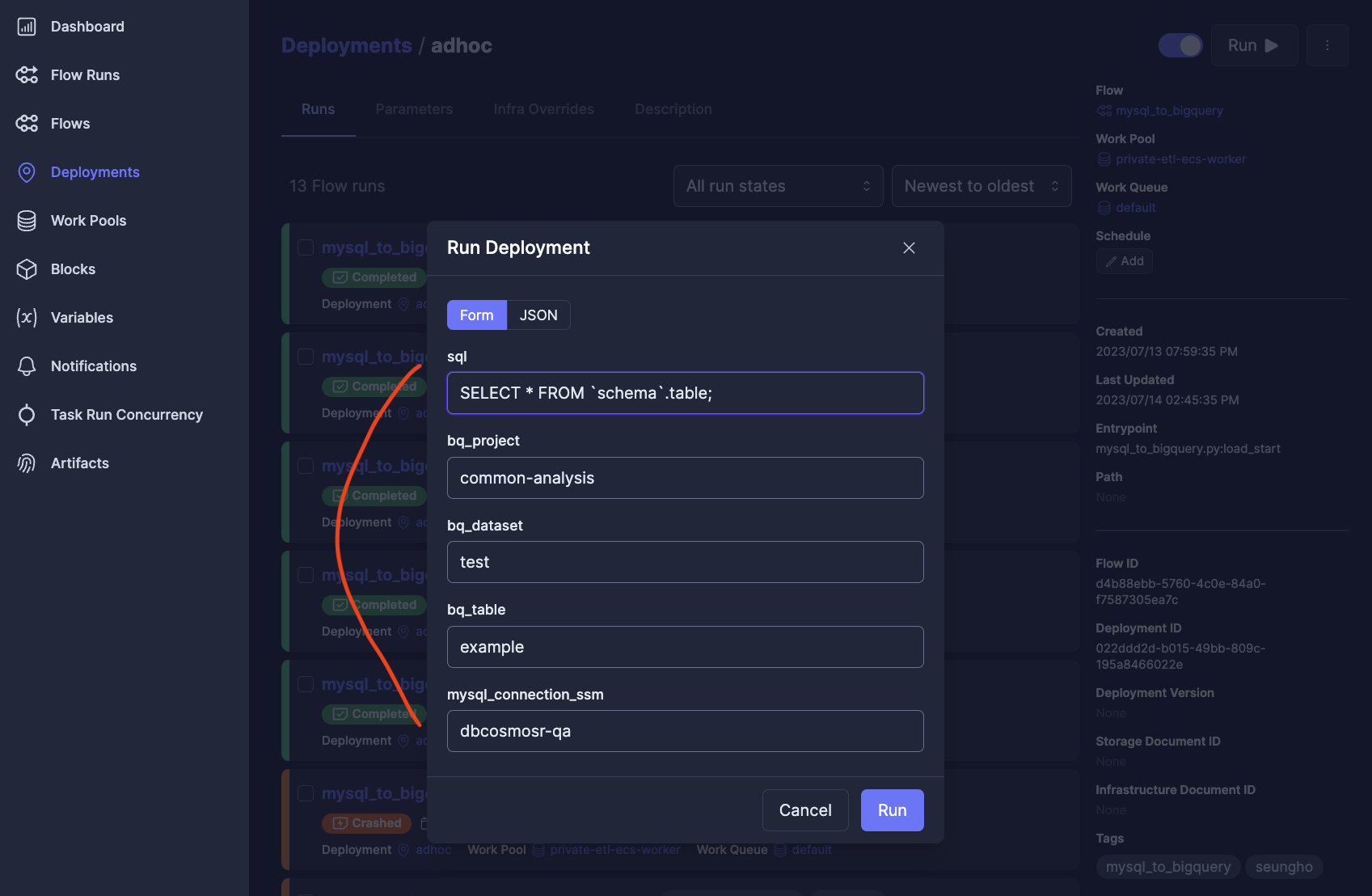
- 장애 발생 시 재처리를 위한 백필 시스템(Prefect Flow) 제공
배운 점과 향후 개선 방향
배운 점
- 데이터 정합성과 백필의 중요성: DAE/DA 분들은 레코드 한건에도 민감하고 원본과의 데이터 정합성이 얼마나 중요한지 분석가분들과 협업해가며 배웠습니다. 정합성을 어떻게 체크하고 모니터링할 것이며 백필 시스템을 어떻게 편하게 구축하여 제공할 지에 대한 중요성을 느꼈던 프로젝트였습니다.
- 관리 리소스 절감의 필요성: 자동 배포와 자동 스키마 추론 등 자동화를 통해 관리 리소스를 절감하여 데이터 엔지니어와의 의존성을 줄이고, 분석가가 직접 테이블을 관리할 수 있는 환경을 조성하는 것이 서로에게 득이 된다는 것을 깨달았고 이러한 리소스 절감들이 더 다양한 분석을 가능하게 한다는 것을 배웠습니다.
향후 개선 방향
- 배포 프로세스 개선: CD를 구축했지만, DMS와 코드를 각각 수정해야 하는 이중 관리의 문제점을 인지했습니다. 이를 하나로 묶어 배포하는 프로세스의 필요성을 느꼈습니다.
- 실시간 데이터 처리: 준실시간을 넘어 로그성 데이터는 완전 실시간(이벤트 로그)으로 처리하는 파이프라인을 구축하고 싶습니다. 기존에 구축된 서비스에서 ETL을 해야 했던 상황적 제약이 아쉬움으로 남습니다.