기술 스택
Snowflake
AI/ML
Python
FastAPI
Docker
개요
메인 프로젝트 외에도, 데이터 엔지니어로서 기술적 전문성을 활용하여 여러 주요 이니셔티브에 기여하며 회사의 데이터 역량 강화와 기술 혁신을 지원했습니다.
1. Snowflake PoC 지원
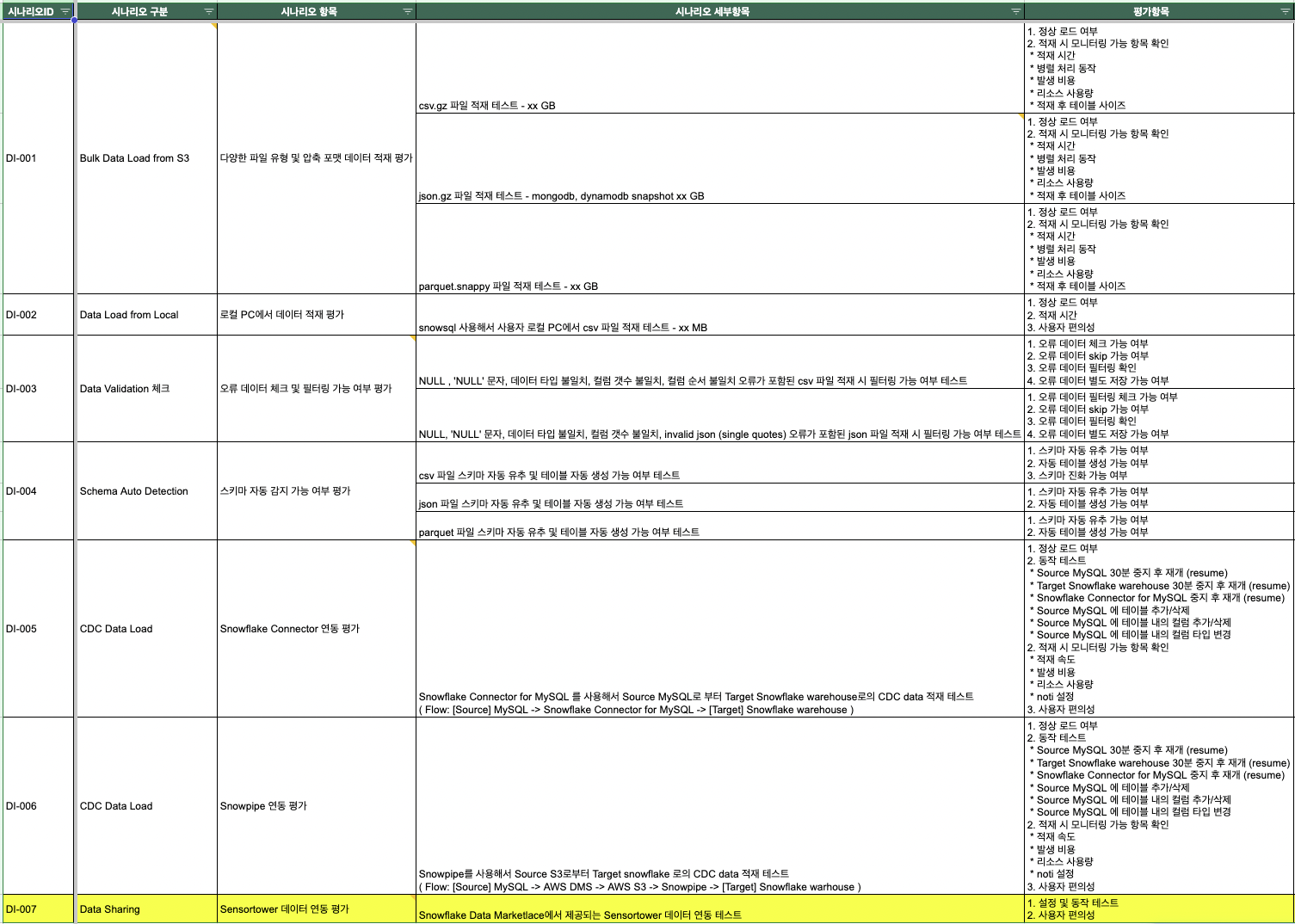
- 개요: 차세대 데이터 웨어하우스 도입을 위해 Redshift와 Snowflake를 비교 검증하는 PoC(Proof of Concept)에 참여했습니다.
- 주요 기여 (Data Ingestion):
- PoC 항목 설계 및 지원: 다양한 데이터 적재 시나리오(실시간, 배치)에 대한 성능 테스트를 문서화하여, 기술 의사결정에 필요한 객관적인 데이터를 제공했습니다. 또한 현재 사용하고 있는 방식뿐만 아니라 Data Sharing, Connector, Snowpipe 등 다양한 기능에 대한 검증도 수행했습니다.
- 실시간 CDC 수집 파이프라인 설계: S3에 데이터가 도착하면 Snowpipe/Lambda를 통해 준실시간으로 Snowflake에 적재되는 자동화 파이프라인을 구축하였습니다.
- 대용량 배치 데이터 적재 최적화:
INFER_SCHEMA,COPY INTO명령어를 활용하여 대용량의 데이터를 S3에서 Snowflake로 로드하는 과정에서 파일 포맷(Parquet), 분할 전략 등을 최적화하여 비용 효율적인 데이터 로딩을 지원했습니다.
- 성과: 안정적이고 효율적인 데이터 수집 방안을 제시하여, Snowflake의 도입 타당성을 검증하고 차세대 아키텍처 설계에 기여했습니다.
2. MCMS (Marketing Cost Management System) 개발 참여
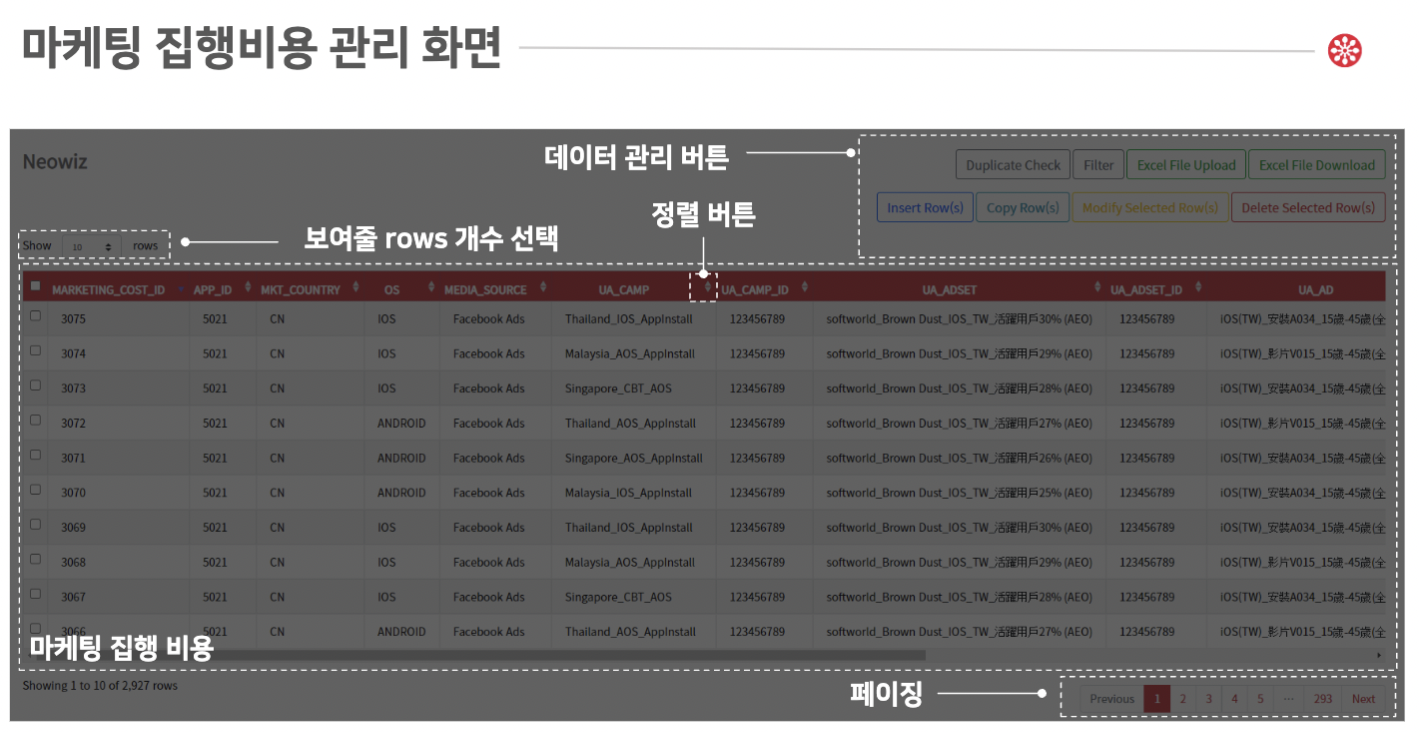
- 개요: 수동으로 입력되어 잦은 오류가 있던 마케팅 비용 데이터 모델링을 개선하기 위해 마케팅 비용을 통합 관리하는 시스템 개발에 참여했습니다.
- 주요 기여:
- 데이터 유효성 검사: 입력된 마케팅 비용 데이터의 정확성을 검증하기 위한 유효성 검사 로직을 구현했습니다. 이로 인하여 배치 로직에서 장애가 월 1회에서 0회로 장애가 없어졌습니다.
- 웹 어플리케이션 구축:
Spring Boot를 사용하여 웹 어플리케이션을 구축하고, 사용자 친화적인 인터페이스를 제공하여 데이터 입력 및 관리의 편의성을 높였습니다.
- 성과: 마케팅 비용 관리 시스템을 만들어 마케팅 비용 배치 프로세스를 안정화하고 데이터 정확성을 높였습니다.
3. 공용 라이브러리 개발
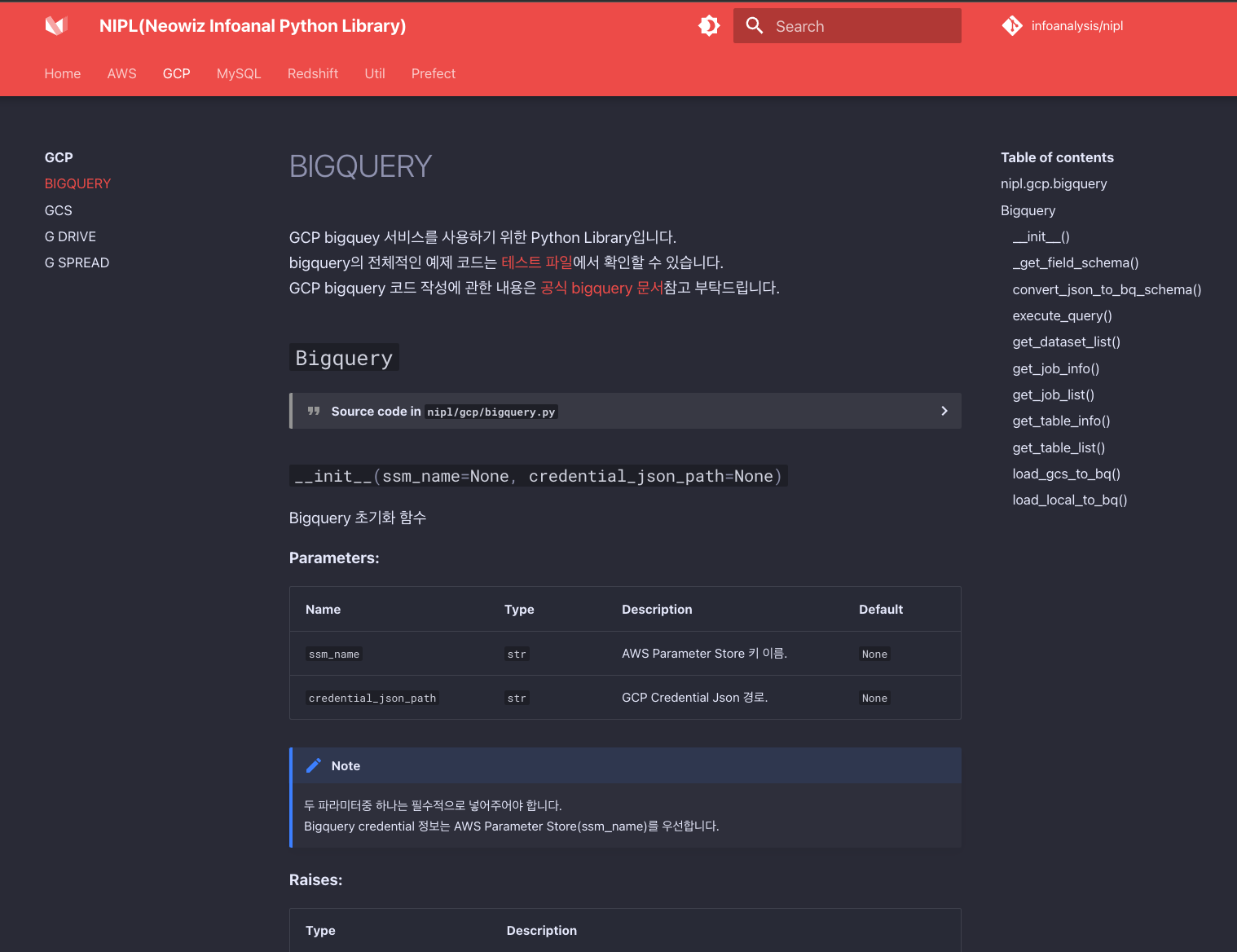
- 개요: 사내 여러 프로젝트에서 반복적으로 사용되는 데이터 처리 로직(추출, 정제, 변환, 집계, 저장)을 표준화하고, 재사용성을 높이기 위한 공용 Python 라이브러리를 개발했습니다.
- 주요 기여:
- 모듈화 및 표준화: 데이터 소스(PostgreSQL, Redshift, S3 등) 연결, 데이터 정제, 집계, S3 저장 등 공통 기능을 모듈화하여 누구나 쉽게 가져다 쓸 수 있도록 설계했습니다.
- 파이프라인 추상화: 복잡한 데이터 처리 과정을 설정 파일(YAML/JSON) 기반으로 정의하고 실행할 수 있는 파이프라인 실행기를 구현하여, 비개발자도 데이터 처리 작업을 쉽게 생성하고 관리할 수 있도록 했습니다.
- 성과: 데이터 관련 개발 생산성을 60% 이상 향상시켰고, 프로젝트 전반의 코드 품질과 일관성을 높였습니다. 신규 입사자도 빠르게 데이터 처리 작업에 적응할 수 있는 기반을 마련했습니다.
4. ML 모델 배포 지원
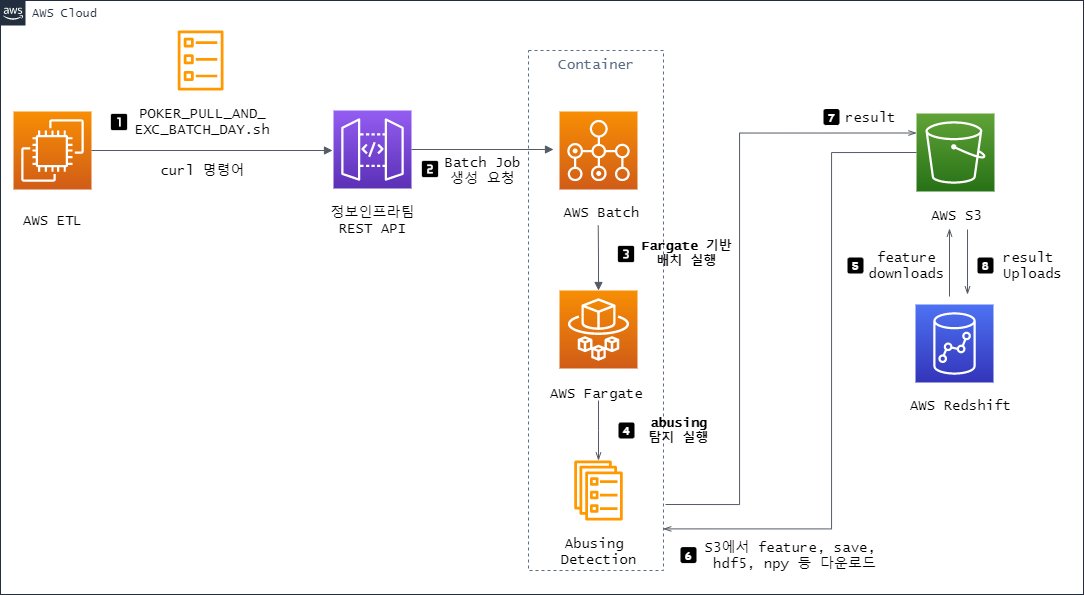
- 개요: 머신러닝 모델 개발 및 운영을 위해 데이터 엔지니어링을 지원하고, MLOps의 기반을 다졌습니다.
- 주요 기여:
- 학습 환경 지원: AWS 인프라에 대한 이해가 부족했던 AI 팀원들에게 AWS 리소스의 사용법을 교육하고, 필요한 환경을 구축하는 데 도움을 주었습니다. 후에는 Sagemaker를 활용한 노트북 기반의 모델 학습 및 배포 파이프라인을 구축했습니다.
- 모델 서빙: 첫 구매 고객 예측, 이탈 유저 예측, 사용자 그룹 모델링 등 다양한 ML 모델의 서빙을 위한 인프라를 구축하고, API를 통해 예측 결과를 제공했습니다.
- 성과: 모델 개발 사이클을 단축하고, 데이터 준비에 드는 시간을 줄여 데이터 사이언티스트가 모델링 자체에 집중할 수 있는 환경을 조성했습니다.
5. 외부 채널링 데이터 제공 API
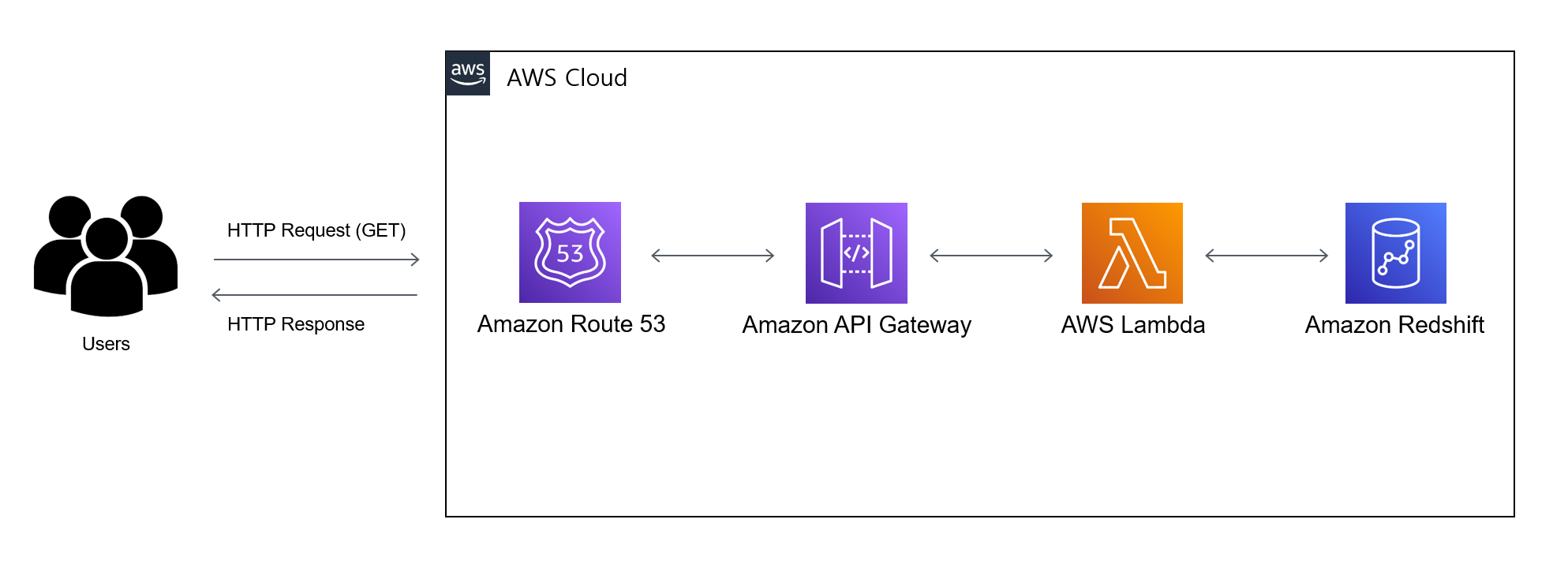
- 개요: 외부 파트너사(채널링 사이트)에 게임 관련 데이터를 안전하게 제공하기 위한 API 서버를 개발했습니다.
- 주요 기여:
- Flask 기반 API 서버 구축: Python의 Flask를 사용하여 API 서버를 구축했습니다. Pydantic을 활용하여 요청 및 응답 데이터의 유효성을 검사하고, 안정적인 데이터 교환을 보장했습니다.
- 보안 및 인증: 외부 파트너사별로 API Key를 발급하고 IP Whitelist를 적용하여 이를 기반으로 요청을 인증하고 권한을 제어하는 로직을 구현하여 데이터 접근을 안전하게 관리했습니다.
- 자동 API 문서화: Swagger를 활용하여 API 문서를 자동으로 생성하고, 파트너사가 쉽게 이해하고 사용할 수 있도록 문서화했습니다.

- 성과: 파트너사가 데이터를 요청하고 수동으로 전달하던 기존 방식을 자동화하여, 데이터 제공에 소요되는 시간을 수일에서 실시간으로 단축시켰습니다. 또한, 표준화된 API를 통해 파트너사와의 협업 효율성을 크게 향상시켰습니다.