기술 스택
Multi-Cloud Real-time Data Pipeline (AWS ↔ GCP)
프로젝트 개요
글로벌 카지노 게임 3종의 일배치를 준실시간 배치로 전환하는 멀티클라우드 데이터 파이프라인 구축 프로젝트입니다. AWS DMS CDC, Lambda, SQS를 활용하여 RDS Aurora의 데이터를 Google BigQuery로 준실시간 이동하며, 일 4,000만 건의 데이터를 99.9% 정합성으로 처리합니다.
🎯 프로젝트 목표
- DB Cluster 6개, 테이블 70여개, 하루 데이터 4,000만 row 처리
- RDB에 저장된 데이터를 평균 지연시간 1-2분으로 실시간 이동
- 실시간 대시보드 및 실시간 FDS(Fraud Detection System) 지원
- 멀티클라우드 환경에서 비용 효율적인 ETL 구현
🏗️ 아키텍처
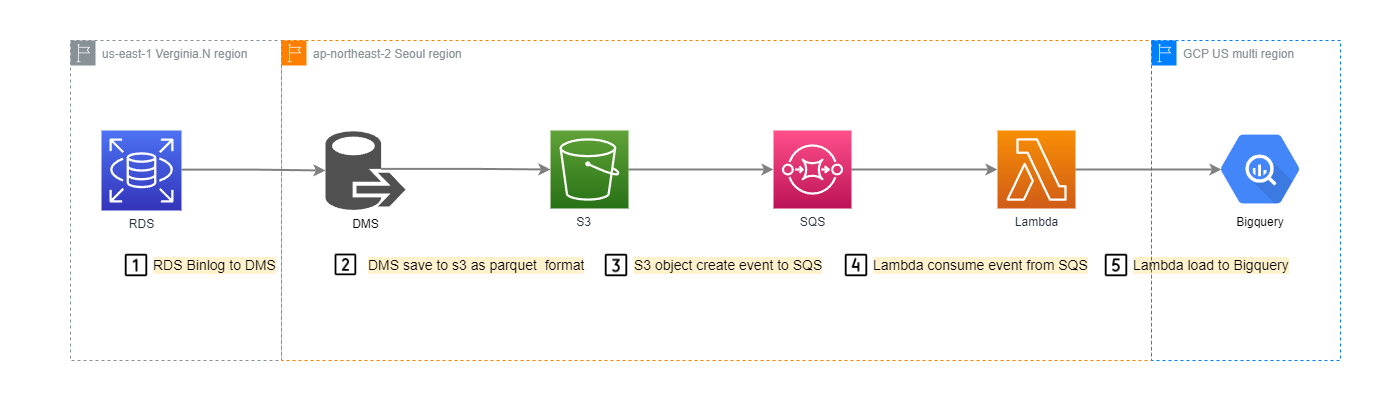
RDS Aurora (MySQL) → AWS DMS (CDC) → S3 → SQS → Lambda → Google BigQuery
핵심 컴포넌트
- AWS DMS: Change Data Capture를 통한 실시간 변경 감지
- Amazon S3: 중간 데이터 저장소 및 버퍼링
- Amazon SQS: 안정적인 메시지 큐잉 및 재처리 지원
- AWS Lambda: 데이터 변환 및 BigQuery 적재 로직
- Google BigQuery: 최종 데이터 웨어하우스
🔧 주요 기술적 도전과 해결
1. 데이터 누락 문제
이슈 - BigQuery API 기반 로드 시 간헐적 오류 발생 - 테이블명, 코드 문법 오류로 인한 로드 실패
해결책 - S3와 Lambda 사이에 SQS 큐 추가로 실패 이벤트 재처리 - Dead Letter Queue 설정으로 완전한 데이터 보장 - 자동 재시도 메커니즘 구현
2. 데이터 중복 문제
이슈 - S3 Event가 "at least once" 방식으로 중복 이벤트 발생 - BigQuery append 방식에서 실패 시 재처리로 인한 중복
해결책
- BigQuery Job ID를 unique identifier로 활용
- yyyymmddhhmmss_{테이블}.parquet 형식의 Job ID로 중복 체크
- 멱등성 보장으로 안전한 재처리 구현
3. 테이블 관리 자동화
이슈 - 테이블 변동이 잦아 매번 수동 배포 필요 - 분석가와 엔지니어 간 커뮤니케이션 비용 증가
해결책 - 테이블 매핑 파일을 별도 관리 - GitLab CI를 통한 자동 배포 구축 - Git 코드에 테이블만 추가하면 자동 반영되는 시스템
4. 자동 스키마 추론
이슈 - MySQL의 Bit, Boolean 타입 지원 문제로 인코딩 깨짐 - 테이블 추가 시 매번 BigQuery 테이블 정의 필요
해결책 - DMS 공통 변환으로 MySQL 라이브러리 이슈 해결 - Parquet 파일 + BigQuery autodetect 스키마 추론 활용 - Parquet + GZ 압축으로 비용 절감 효과 달성
📊 성과 및 임팩트
비즈니스 임팩트
- 실시간 대시보드 구현으로 즉시 의사결정 지원
- 실시간 FDS 구축으로 부정 거래 실시간 탐지
- 분석가의 ETL 파이프라인 관리 리소스 최소화
기술적 성과
- 평균 지연시간: 1-2분의 준실시간 처리
- 데이터 정합성: 99.9% 달성
- 처리량: 일 4,000만 건 안정적 처리
- 비용: 월 $150로 비용 효율적 운영
운영 효율성
- 자동화된 테이블 관리로 엔지니어 개입 최소화
- 모니터링 대시보드로 분석가 문의 최소화
- 백필 시스템 제공으로 장애 시 빠른 복구
🔍 모니터링 및 관리
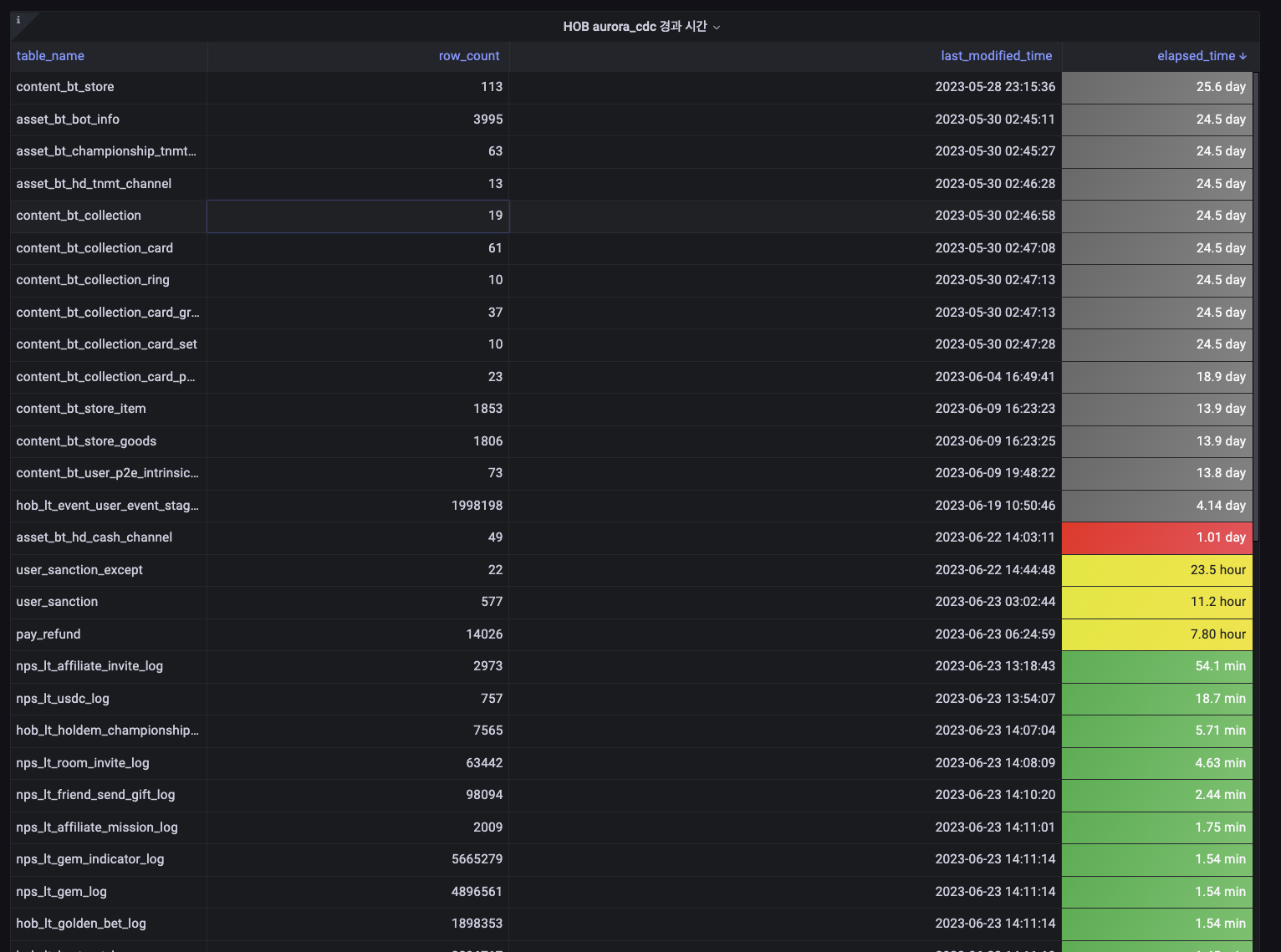
실시간 모니터링
- 테이블 현황 대시보드 구축
- 데이터 수집 상태 실시간 확인
- BigQuery 한도 체크 및 비용 모니터링
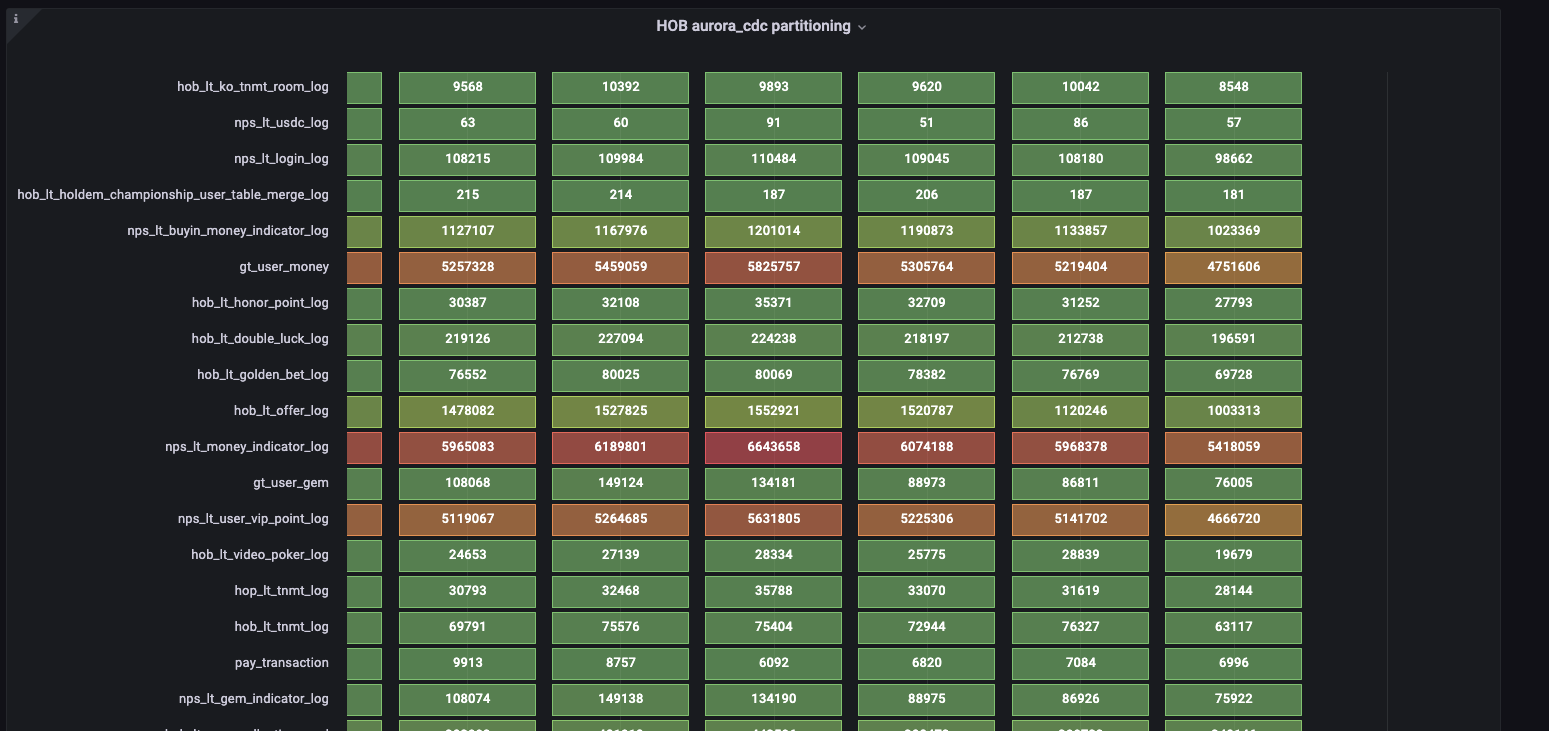
장애 대응 시스템
- Google Spreadsheet + DMS FullLoad 재처리 시스템
- CDC 형태 데이터로 이력성 테이블 관리
- 자동 알림 및 에스컬레이션 정책
🚀 기술적 혁신
1. 멀티클라우드 아키텍처
- AWS와 GCP 간 효율적인 데이터 이동
- 각 클라우드의 장점을 활용한 최적화
- 클라우드 벤더 종속성 최소화
2. 실시간 CDC 파이프라인
- 기존 배치 처리에서 실시간 처리로 패러다임 전환
- Change Data Capture를 통한 최소 지연시간 달성
- 스냅샷성이 아닌 이력성 데이터 관리
3. 자동화 및 셀프서비스
- 분석가가 직접 테이블 관리 가능
- 엔지니어 의존성 최소화
- 코드 기반 인프라 관리
📈 확장성 및 재사용성
이 프로젝트는 다른 게임 및 서비스로 확장 가능한 재사용 가능한 아키텍처로 설계되었습니다:
- 템플릿화된 DMS 설정
- 공통 Lambda 함수 활용
- 표준화된 모니터링 체계
- 문서화된 운영 가이드
🎓 학습 및 성장
기술적 학습
- 멀티클라우드 아키텍처 설계 경험
- 대용량 실시간 데이터 처리 노하우
- AWS DMS 심화 활용법
- BigQuery 최적화 기법
비즈니스 임팩트
- 데이터 기반 의사결정 문화 확산
- 실시간 분석 환경 구축
- 운영 효율성 극대화
- 비용 최적화 달성
이 프로젝트를 통해 데이터 엔지니어링의 전 영역을 경험하며, 기술적 우수성과 비즈니스 가치를 동시에 달성하는 능력을 입증했습니다.