기술 스택
Amazon MSK
DynamoDB Streams
MSK Connect
AWS Lambda
Python
프로젝트 개요
기존 RDB 중심의 데이터 수집 방식으로는 클라이언트 로그와 같이 비정형적이고 실시간성이 강한 데이터를 처리하는 데 한계가 있었습니다. 또한, DynamoDB와 같은 반정형 데이터베이스의 이벤트 로그를 실시간으로 수집하고 분석하는 데 필요한 인프라가 부족했습니다.
본 프로젝트는 Amazon MSK를 중앙 데이터 허브로 구축하여 모든 이벤트 로그 데이터의 수집을 표준화하고, 이를 데이터 웨어하우스(DW) 및 다양한 타겟 시스템에 안정적으로 연동하는 대용량 스트리밍 데이터 수집 플랫폼을 구축하는 것을 목표로 했습니다.
아키텍처
MSK
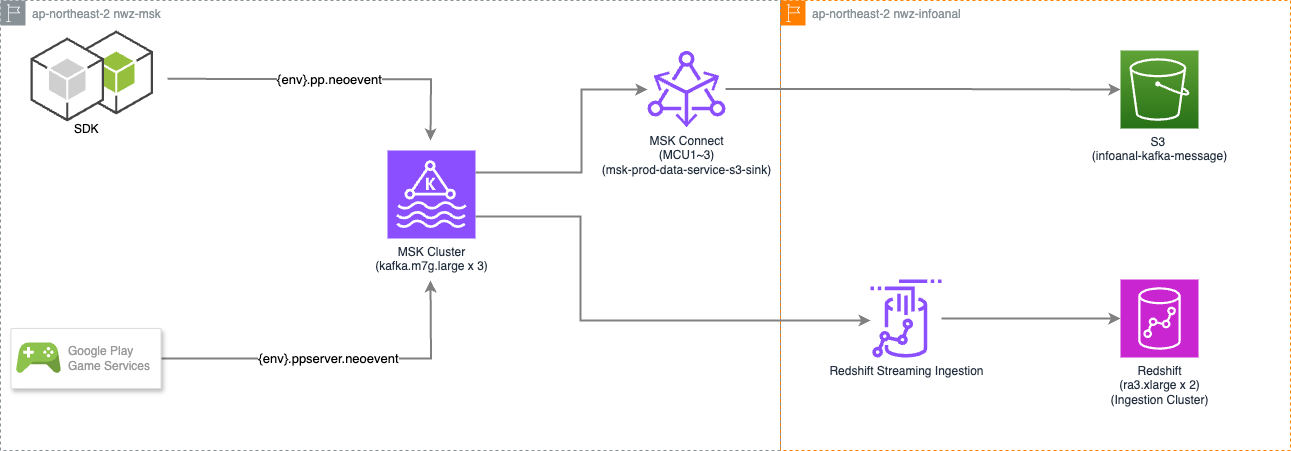
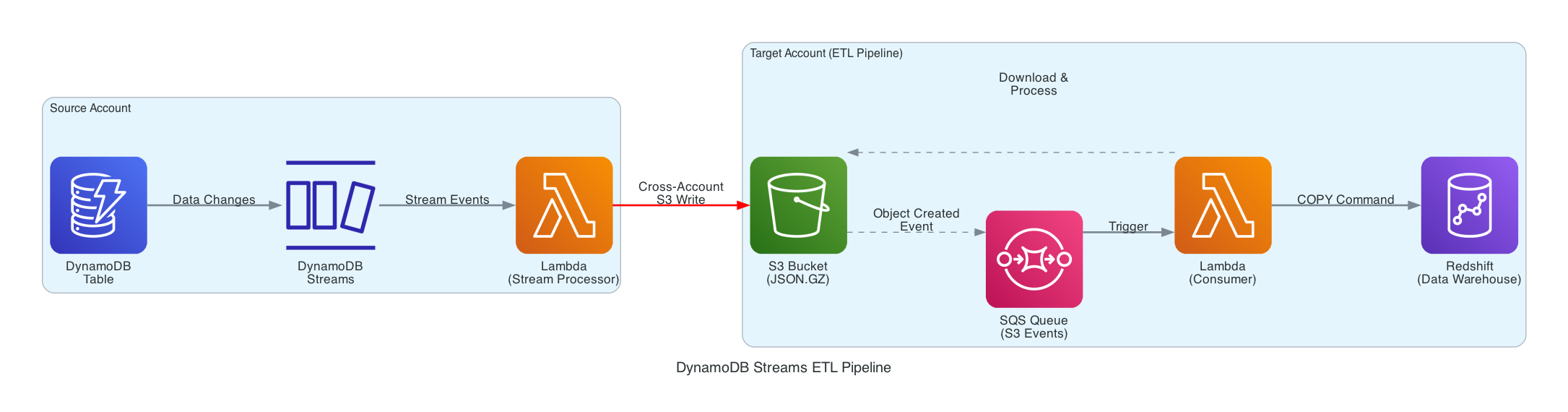
DynamoDB Streams
프로젝트 목표
- 전사 데이터 허브 구축: 파편화된 데이터 수집 파이프라인을 MSK 기반으로 통합하여, 클라이언트, 서버 등 모든 소스에서 발생하는 데이터를 한곳으로 모으는 중앙 데이터 허브를 구축합니다.
- 안정적인 DW 연동 파이프라인 구축: MSK, DynamoDB 데이터를 데이터 분석가들이 활용할 수 있도록 안정적으로 DW(S3, Redshift)에 적재하고 분석이 가능한 형태로 변환합니다.
- 실시간 데이터 처리 기반 마련: 급증하는 이벤트성 데이터를 지연 없이 처리하고, 이를 실시간 대시보드, 모니터링 등 다양한 서비스에서 활용할 수 있는 기반을 마련합니다. t
기술적 도전과 해결 과정
1. MSK Connect를 활용한 다양한 타겟으로의 Code-less 데이터 파이프라인 구축
- 문제: 중앙 허브인 MSK로 수집된 데이터를 분석으로 활용하기 위해 다양한 타겟으로의 적재를 희망하였고, 이를 위한 별도의 개발 리소스도 부족하였고 경험도 전무하였습니다.
- 해결: s3, redshift, bigquery, snowflake 로의 모든 타겟으로의 테스트 및 연동을 마쳤고, MSK Connect를 도입하여 별도의 개발 과정 없이 커넥터 설정만으로 다양한 타겟 시스템에 데이터를 연동했습니다. 이를 통해 파이프라인 구축 시간을 단축하고, 검증된 커넥터를 활용하여 데이터 전송의 안정성을 확보했습니다.
- Redshift 연동 예시 (Materialized View 활용): Redshift Streamin Ingestion을 활용해 MSK 토픽을 직접 조회할 수 있는 외부 스키마와 Materialized View를 생성하여, SQL만으로 실시간 데이터에 접근할 수 있는 환경을 구축했습니다.
-- 외부 스키마 생성 (MSK 브로커 연동)
CREATE EXTERNAL SCHEMA kafka_schema
FROM KAFKA
AUTHENTICATION NONE
URI 'b-1.msk-prod-cluster.xxxxxx.c4.kafka.ap-northeast-2.amazonaws.com:9094,b-2.msk-prod-cluster.xxxxxx.c4.kafka.ap-northeast-2.amazonaws.com:9094'
-- Materialized View 생성 (특정 토픽 구독)
CREATE MATERIALIZED VIEW my_schema.my_event_view AUTO REFRESH YES AS
SELECT *
FROM kafka_schema."dev.service.myevent";
-- SUPER 타입의 JSON 데이터 파싱 조회
SELECT
parsed_json.app.id::INT AS app_id,
parsed_json.app.version AS app_version,
parsed_json.device.id AS device_id
FROM (
SELECT json_parse(kafka_value) AS parsed_json
FROM my_schema.my_event_view
);
- Snowflake 연동 예시 (Sink Connector 설정): Snowflake Sink Connector의 Properties 파일을 설정하여 MSK의 특정 토픽 데이터를 Snowflake 테이블로 자동 적재하도록 구성했습니다.
# Snowflake Sink Connector Properties
connector.class=com.snowflake.kafka.connector.SnowflakeSinkConnector
tasks.max=2
topics=dev.pp.neoevent,dev.ppserver.neoevent
snowflake.topic2table.map=dev.pp.neoevent:dev_pp_neoevent,dev.ppserver.neoevent:dev_ppserver_neoevent
# Snowflake Connection Info
snowflake.url.name=xxxxxxxx-xxxxxxxx.snowflakecomputing.com:443
snowflake.user.name=msk_user
snowflake.private.key=MIIFNTBf... (Secret)
snowflake.private.key.passphrase=************
snowflake.database.name=msk_db
snowflake.schema.name=msk_schema
# Buffer & Converter Settings
buffer.count.records=10000
buffer.flush.time=60
buffer.size.bytes=5000000
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=com.snowflake.kafka.connector.records.SnowflakeJsonConverter
2. DynamoDB Streams를 활용한 안정적인 CDC 데이터 처리
2-1. 대용량 트래픽의 안정적인 처리
- 문제: 이벤트 기간 동안 예측 불가능한 트래픽이 예상되어 스트림 처리의 안정성이 우려되었습니다.
- 해결: 분당 1000만건의 스트레스 테스트를 통해 시스템의 한계를 파악하고, Lambda의
batch_size와 SQS의maximum_batching_window_in_seconds를 최적화하여 대규모 이벤트를 효율적으로 그룹화하고 처리할 수 있도록 구성했습니다. 이를 통해 피크 타임에도 안정적인 데이터 처리를 보장했습니다.
2-2. CDC 데이터의 멱등성 있는 처리
- 문제: DynamoDB Streams에서 제공되는
INSERT,MODIFY,REMOVE이벤트 형식으로 발생하는 JSON 데이터를 분석가가 활용할 수 있도록 가공하고 안정적인 테이블 구조를 가질 필요가 있었습니다.
-- 예시 records
{
"Records":[
{
"eventID":"1",
"eventName":"INSERT",
"eventVersion":"1.0",
"eventSource":"aws:dynamodb",
"awsRegion":"us-east-1",
"dynamodb":{
"Keys":{
"Id":{
"N":"101"
}
},
"NewImage":{
"Message":{
"S":"New item!"
},
"Id":{
"N":"101"
}
},
"SequenceNumber":"111",
"SizeBytes":26,
"StreamViewType":"NEW_AND_OLD_IMAGES"
},
"eventSourceARN":"stream-ARN"
},
{
"eventID":"2",
"eventName":"MODIFY",
"eventVersion":"1.0",
"eventSource":"aws:dynamodb",
"awsRegion":"us-east-1",
"dynamodb":{
"Keys":{
"Id":{
"N":"101"
}
},
"NewImage":{
"Message":{
"S":"This item has changed"
},
"Id":{
"N":"101"
}
},
"OldImage":{
"Message":{
"S":"New item!"
},
"Id":{
"N":"101"
}
},
"SequenceNumber":"222",
"SizeBytes":59,
"StreamViewType":"NEW_AND_OLD_IMAGES"
},
"eventSourceARN":"stream-ARN"
},
{
"eventID":"3",
"eventName":"REMOVE",
"eventVersion":"1.0",
"eventSource":"aws:dynamodb",
"awsRegion":"us-east-1",
"dynamodb":{
"Keys":{
"Id":{
"N":"101"
}
},
"OldImage":{
"Message":{
"S":"This item has changed"
},
"Id":{
"N":"101"
}
},
"SequenceNumber":"333",
"SizeBytes":38,
"StreamViewType":"NEW_AND_OLD_IMAGES"
},
"eventSourceARN":"stream-ARN"
}
]
}
- 해결:
raw 테이블과state 테이블로 나누어 테이블을 설계하고 데이터의 최종 상태를 정확하게 반영하기 위해 멱등성을 보장하는 UPSERT 쿼리를 설계했습니다. 임시 테이블(Stage)을 활용하여 특정 시간 범위 내의 이벤트 중 가장 최신 이벤트만 선별하고,updatedAt과sequence_number를 복합적으로 사용하여 순서가 보장된 데이터 변경을 수행했습니다.
-- DynamoDB Streams CDC 데이터를 Redshift State 테이블에 MERGE하는 쿼리
BEGIN;
-- 1단계: 임시 테이블에 최신 이벤트만 선별하여 저장
CREATE TEMP TABLE stage_events AS
SELECT pk, sk, event_name, approximate_creation_date_time, sequence_number, new_image
FROM (
SELECT *, ROW_NUMBER() OVER (
PARTITION BY pk, sk
ORDER BY
CASE WHEN event_name = 'REMOVE' THEN 1 ELSE 0 END DESC,
COALESCE(CAST(new_image.updatedAt.N AS BIGINT), 0) DESC,
approximate_creation_date_time DESC,
COALESCE(CAST(sequence_number AS DECIMAL(38,0)), 0) DESC
) AS rn
FROM my_schema.my_raw_table
WHERE creation_time BETWEEN '2025-08-17 14:40:41.135' AND '2025-08-17 14:44:54.010'
) t WHERE rn = 1;
-- 2단계: 'MODIFY' 이벤트 업데이트
UPDATE my_schema.my_state_table SET ... FROM stage_events WHERE ...;
-- 3단계: 'INSERT' 또는 새로운 'MODIFY' 이벤트 삽입
INSERT INTO my_schema.my_state_table (...) SELECT ... FROM stage_events WHERE ...;
-- 4단계: 'REMOVE' 이벤트 삭제
DELETE FROM my_schema.my_state_table USING stage_events WHERE ...;
DROP TABLE stage_events;
END;
2-3. 안전한 데이터 공유를 위한 Cross-Account 접근 제어
- 문제: 타 계정에서 발생한 DynamoDB 데이터를 직접적인 DB 접근 권한 없이 실시간으로 분석실로 데이터를 옮길 방법이 필요했습니다.
- 해결: 타 부서가 저희 DynamoDB Streams에 직접 접근할 수 있도록, Terraform으로 IAM Role과 Policy가 정의된 템플릿을 제작하여 제공했습니다. 이를 통해 타 부서는 필요한 최소한의 권한만 안전하게 획득하고, 저희는
S3 Bucket Policy를 통해 접근 제어를 유지하며 효율적으로 데이터를 공유할 수 있었습니다.
# IAM 역할 및 정책 생성 (Lambda가 DynamoDB Stream을 읽고 S3에 쓰도록 허용)
resource "aws_iam_role" "dynamodb_stream_role" { ... }
resource "aws_iam_policy" "dynamodb_stream_policy" { ... }
resource "aws_iam_role_policy_attachment" "dynamodb_stream_attachment" { ... }
# Lambda 함수 및 이벤트 소스 매핑
resource "aws_lambda_function" "dynamodb_stream_consumer" {
function_name = "dynamodb-stream-to-s3"
role = aws_iam_role.dynamodb_stream_role.arn
...
}
resource "aws_lambda_event_source_mapping" "dynamodb_stream_mapping" {
event_source_arn = "arn:aws:dynamodb:ap-northeast-2:123456789012:table/MyTable/stream/..."
function_name = aws_lambda_function.dynamodb_stream_consumer.arn
starting_position = "TRIM_HORIZON"
batch_size = 100000
maximum_batching_window_in_seconds = 5
}
성과 및 임팩트
- 분석 영역의 확장: 기존 RDB 데이터만으로는 불가능했던 클라이언트단 사용자의 상세 행동 패턴, UI 인터랙션 등 이벤트 기반의 심층 분석이 가능해졌습니다.
- 전사 데이터 통합 및 협업 기반 마련: MSK를 중앙 허브로 구축하여 데이터 사일로(Silo)를 해소하고, 다른 부서가 필요한 데이터를 손쉽게 구독하여 새로운 비즈니스 가치를 창출할 수 있는 협업의 기틀을 마련했습니다.
- 데이터 수집의 표준화 및 안정성 증대: 데이터 로깅 포맷을 표준화하고 파이프라인을 일원화하여 데이터의 품질과 신뢰도를 높였으며, 대규모 트래픽에도 안정적인 데이터 수집을 보장하게 되었습니다.
배운 점과 향후 개선 방향
배운 점
- 전사적 큐의 전략적 가치: 중앙 집중식 메시지 큐(MSK)가 단순히 데이터를 전달하는 기술적 요소를 넘어, 전사의 데이터 흐름을 하나로 묶고 부서 간 협업을 촉진하는 핵심적인 전략 자산임을 깨달았습니다.
- 데이터 정합성을 위한 멱등성 설계의 중요성: CDC(Change Data Capture) 데이터를 처리할 때,
INSERT,UPDATE,DELETE이벤트의 순서가 보장되지 않거나 중복 발생 가능성이 항상 존재함을 인지했습니다.UPSERT쿼리 설계 시 단순히 최신 데이터만 반영하는 것을 넘어,sequence_number와 같은 보조 정렬 키를 활용하여 데이터의 최종 상태를 보장하는 견고한 멱등성 로직을 구현하는 것이 얼마나 중요한지 깊이 깨달았습니다. - 대용량 스트리밍 데이터 처리의 핵심, 배치 최적화: 이론으로만 알던 대용량 데이터 처리를 실제로 경험하며, Lambda의
batch_size나 SQS의maximum_batching_window_in_seconds같은 파라미터 하나가 전체 파이프라인의 안정성에 얼마나 큰 영향을 미치는지 체감했습니다. 스트레스 테스트를 통해 병목 지점을 파악하고, 시스템의 특성에 맞게 배치를 최적화하는 과정이 안정적인 스트리밍 플랫폼 구축의 핵심임을 배웠습니다.
향후 개선 방향
- 실시간 분석 피드백 루프 구축: 현재의 데이터 수집 단계를 넘어, Apache Flink와 같은 스트림 처리 엔진을 도입하여 실시간으로 데이터를 분석하고, 그 결과를 게임 밸런싱이나 개인화 추천 등 실제 서비스에 다시 반영하는 진정한 의미의 실시간 분석 서비스를 구현하고 싶습니다.
- MSK Connect 모니터링 강화: MSK Connect의 운영 안정성을 더욱 높이기 위해 커넥터의 상태, 처리량, 지연 시간 등에 대한 세분화된 모니터링 및 알림 체계를 구축하여 장애 발생 시 더욱 신속하게 대응할 계획입니다.