기술 스택
OpenAI GPT
LangChain
Chainlit
FastAPI
Langfuse
PostgreSQL
프로젝트 개요
반복적인 Ad-hoc 데이터 추출 요청으로 인해 데이터 팀의 리소스가 분산되는 문제를 해결하기 위해, LLM(Large Language Model)을 활용한 Text-to-SQL 시스템을 구축했습니다. 이 시스템은 비개발자가 자연어 질문을 통해 직접 데이터를 조회할 수 있는 환경을 제공하여, 데이터 접근성을 획기적으로 개선하고 분석 요청을 40% 감소시키는 성과를 달성했습니다.
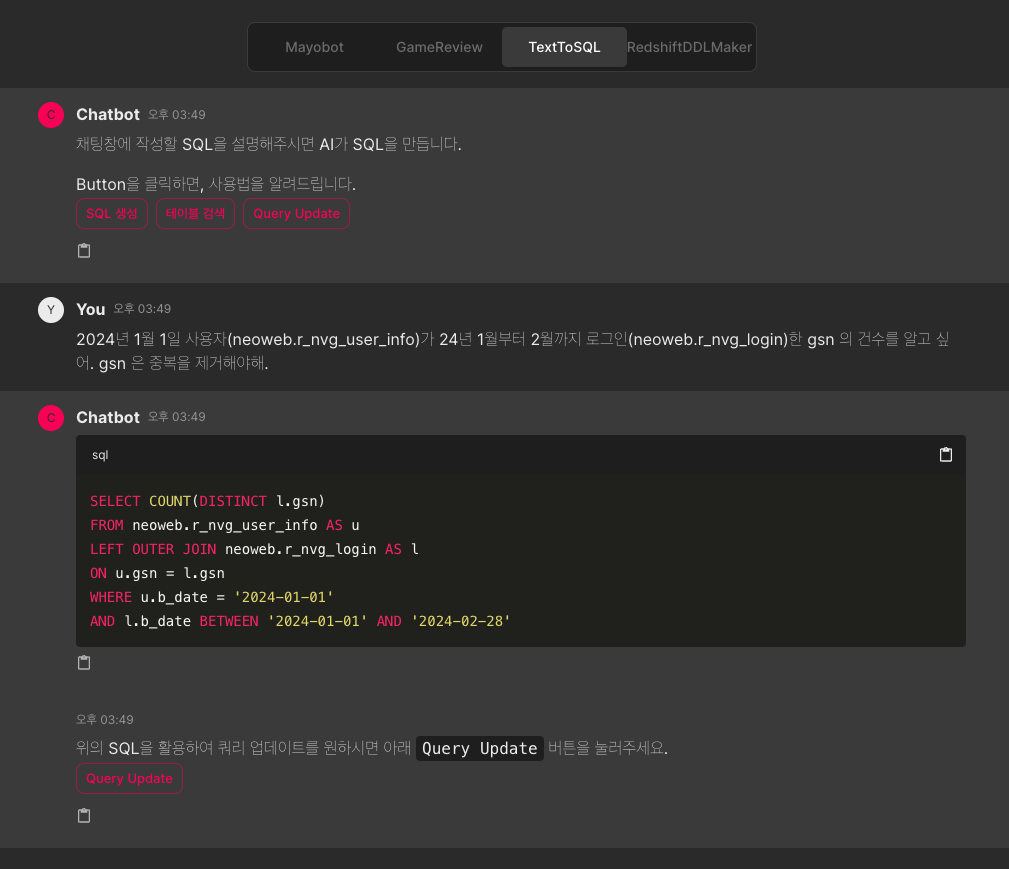
프로젝트 목표
- 데이터 민주화 및 업무 효율성 증대: 분석가나 SQL에 익숙하지 않은 팀원들도 직접 데이터를 탐색하고 인사이트를 얻을 수 있는 셀프 서빙(Self-Serving) 환경을 구축하여, 반복적인 데이터 추출 업무를 자동화하고 데이터 팀의 핵심 업무 집중도를 높입니다.
- LLM 기반 애플리케이션 구축 역량 내재화: Text-to-SQL 시스템을 직접 설계하고 개발하며 RAG(Retrieval-Augmented Generation), 프롬프트 엔지니어링, LLM 운영(LLMOps) 등 최신 AI 기술에 대한 깊은 이해와 실전 경험을 확보합니다.
- 사용자 친화적인 분석 경험 제공: 복잡한 SQL 지식 없이도 대화형 인터페이스를 통해 원하는 데이터를 얻을 수 있도록 하여, 데이터 기반의 빠른 의사결정을 지원하고 사내에 성공적인 AI 도입 사례를 전파합니다.
기술적 도전과 해결 과정
1. RAG 정확도 향상을 통한 신뢰성 있는 SQL 생성
- 과제: 사용자의 모호한 자연어 질문을 정확한 SQL로 변환하기 위해서는, LLM이 데이터베이스의 스키마(테이블, 컬럼, 관계)를 완벽하게 이해해야 했습니다. 단순한 키워드 검색만으로는 복잡한 조인이나 조건을 처리하는 데 한계가 있었습니다.
- 해결:
- 하이브리드 검색(Hybrid Search) 도입: 단순히 벡터 유사도(pgvecto) 검색으로는 세부적인 필터를 걸 수 없어 record마다 메타데이터를 두어 메타데이터 검색을 같이 진행하여 검색 정확도를 높였습니다.
- 상세 정보 임베딩: 테이블, 컬럼명뿐만 아니라 컬럼에 대한 설명, 데이터 타입, 샘플 값까지 임베딩하여 LLM이 컨텍스트를 더 풍부하게 이해하도록 했습니다.
- Re-ranker 적용: 1차적으로 검색된 테이블들을 Re-ranker로 재정렬하여, 질문과 가장 관련성이 높은 정보를 프롬프트에 우선적으로 포함시켜 SQL 생성의 정확도를 극대화했습니다.
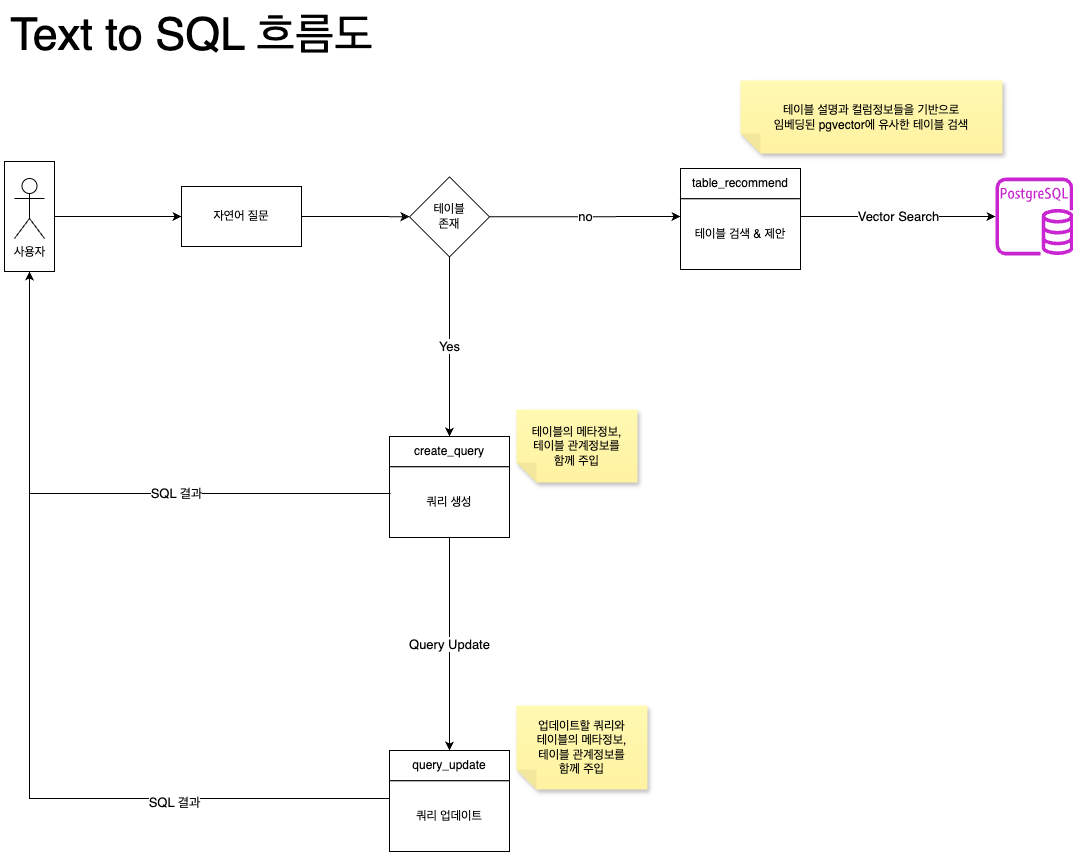
2. 프롬프트 엔지니어링 및 추적 시스템 구축
- 과제: LLM의 응답은 프롬프트에 따라 크게 달라지기 때문에, 일관성 있고 안정적인 성능을 보장하기 위한 체계적인 프롬프트 관리 및 디버깅 시스템이 필요했습니다.
- 해결:
- Few-shot 프롬프팅: 복잡한 질문 유형(예: 특정 기간 비교, 사용자 그룹 정의)에 대한 질문-SQL 예시 쌍을 프롬프트에 동적으로 포함시켜, LLM이 복잡한 쿼리도 효과적으로 생성하도록 유도했습니다.
- Langfuse 도입: LLM의 입출력, 중간 과정, 비용, 지연 시간 등 모든 과정을 추적하고 분석하기 위해 오픈소스 LLMOps 도구인 Langfuse를 도입했습니다. 이를 통해 "Black Box" 같던 LLM의 작동을 가시화하고, 문제 발생 시 신속하게 원인을 파악하고 프롬프트를 개선할 수 있었습니다.
3. 대화의 연속성을 위한 메모리 관리
- 과제: 사용자가 "방금 그 결과에서 한국 사용자만 보여줘"와 같이 이전 질문에 이어서 질문할 때, 시스템이 대화의 맥락을 이해하고 후속 쿼리를 생성해야 했습니다.
- 해결: Conversation Buffer Memory를 구현하여 사용자와의 대화 기록을 관리했습니다. 새로운 질문이 들어오면 이전 대화 내용을 함께 프롬프트에 포함시켜, LLM이 전체 대화의 맥락을 기반으로 답변을 생성하도록 하여 사용자 편의성을 높였습니다.
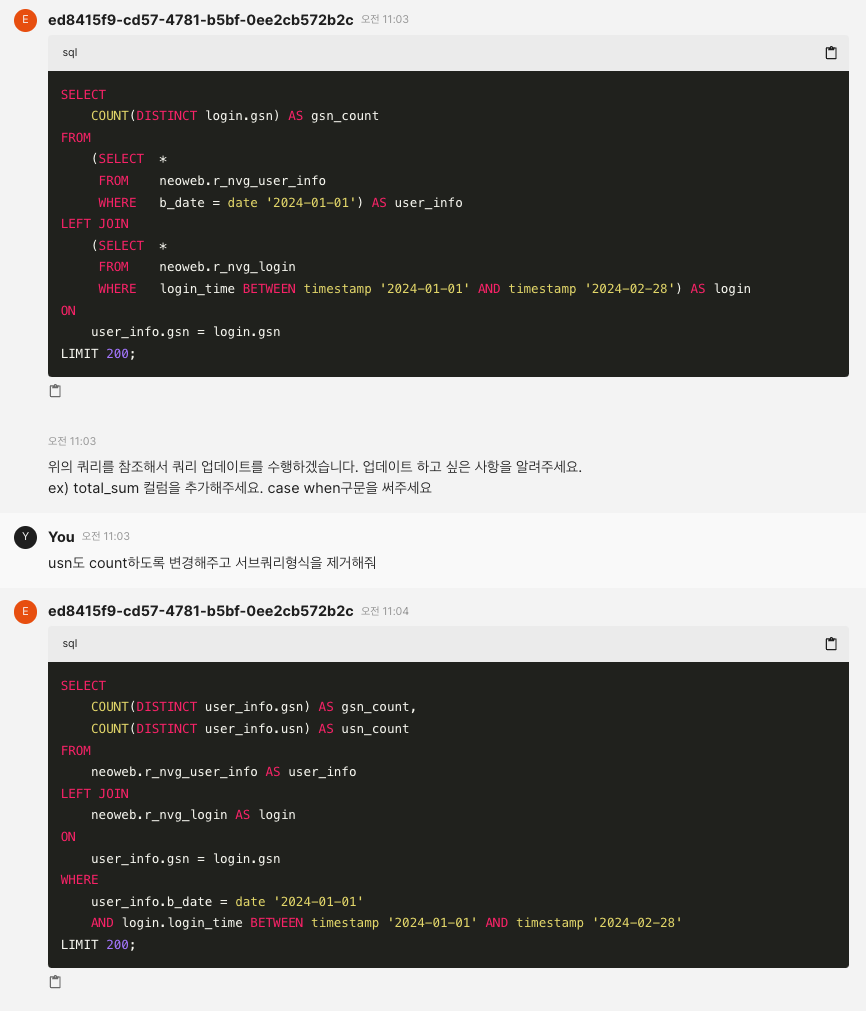
성과 및 임팩트
- 쿼리 요청 감소: 데이터 팀에 인입되던 단순 데이터 추출 요청이 40% 감소했으며, 평균 응답 시간 또한 수 시간에서 분 단위로 단축되었습니다.
- 전사적 데이터 활용 문화 확산: 비개발 직군도 데이터에 쉽게 접근할 수 있게 되면서, 데이터 기반의 커뮤니케이션이 활성화되고 사내에 RAG의 효용성과 성공적인 AI 도입 사례를 전파했습니다.
- 엔지니어링 생산성 증대: 반복 업무에서 벗어난 데이터 엔지니어들이 고부가가치 분석 모델링 및 데이터 플랫폼 개선에 더 많은 시간을 투입할 수 있게 되었습니다.
배운 점과 향후 개선 방향
배운 점
- LLM 애플리케이션의 전체 생명주기 경험: 아이디어 구상부터 RAG 파이프라인 설계, 프롬프트 엔지니어링, Langfuse를 이용한 성능 추적 및 개선까지, LLM 기반 서비스를 개발하고 운영하는 전 과정을 경험하며 실전 역량을 쌓았습니다. 단순히 모델을 호출하는 것을 넘어, 안정적인 서비스를 만들기 위한 종합적인 접근 방식의 중요성을 깨달았습니다.
- 관찰 가능성(Observability) 기반의 신뢰성 확보: Langfuse와 같은 추적 도구를 통해 LLM의 작동을 모니터링하는 것은 단순한 디버깅을 넘어, 서비스의 신뢰성을 확보하고 지속적으로 성능을 개선하기 위한 필수 요소임을 깨달았습니다. 모든 요청과 응답, 중간 과정을 추적하며 데이터 기반으로 시스템을 개선하는 방법을 체득했습니다.
향후 개선 방향
- 객관적인 성능 평가 체계 도입: Ragas와 같은 벤치마크 프레임워크를 도입하여 SQL 생성의 정확도, 재현율 등을 객관적인 지표로 관리하고, 지속적인 성능 개선의 기준으로 삼을 계획입니다.
- 시맨틱 레이어(Semantic Layer) 구축: 사용자가 비즈니스 용어(예: '총매출', '활성 유저')로 질문하면, 이를 시스템이 사전에 정의된 SQL 로직으로 변환해주는 시맨틱 레이어를 도입하여 쿼리의 정확성과 일관성을 높이고자 합니다.
- 개인화 및 보안 강화 (MCP 도입): 사내 인증 시스템과 연동하여 사용자별로 접근 가능한 데이터베이스나 테이블 권한을 제어하고, 개인의 사용 이력을 기반으로 맞춤형 질문을 추천하는 등 사용자 친화적인 기능을 강화할 것입니다. 향후 MCP(Model-Context-Protocol)를 도입하여 모델이 사용자의 컨텍스트(권한, 소속 부서 등)를 안전하게 인식하고, 더욱 개인화되고 안전한 쿼리를 생성하도록 시스템을 고도화할 계획입니다.